
Auf dieser Seite sammle ich zum Nachlesen und Lernen, was ich in meinem Unterricht zum Thema Genetik in den Jahrgangsstufen 9 und 10 leider nicht vermitteln soll.
|
Vom Gen zum Genprodukt |
|---|---|
|
Transkription |
|
Translation |
|
mein einfaches Kreislaufschema der Translation |
|
Das Erbmaterial aller Prokaryoten und Eukaryoten heißt DNA. Deren spezielle Struktur macht es möglich, in ihr Erbinformationen zu speichern und Kopien davon zu machen. Zellen speichern (codieren) in der DNA die Bauanleitungen für Proteine und RNAs.
Vom Gen zum Genprodukt
|
|---|
Der in DNA gespeicherte Bauplan (Genom) befindet sich bei noch teilungsfähigen eukaryotischen Zelle im Zellkern. Die genetische Information eines Gens steckt in der Reihenfolge (Sequenz) der Nukleotide, so wie sich die Bedeutung eines Wortes aus der Reihenfolge seiner Buchstaben ergibt. Und wie die wertvollsten Bücher einer Bibliothek nur fotografiert oder photokopiert und nicht ausgeliehen werden, so verlässt auch die DNA nicht den Zellkern. Braucht eine Zelle ein Rezept für ein bestimmtes Protein, dann werden im Zellkern von dem entsprechenden Gen in einem Transkription genannten Prozess Umschriften (Kopien auf den etwas anderen Informationsträger RNA) gemacht.
Die Informationen werden nicht einfach kopiert, weil die RNA etwas andere Nukleotide als die DNA enthält. Es passiert eher ein Umschreiben wie die Übertragung eines in kyrillischer Schrift vorliegenden Originals in einen Text mit lateinischen Buchstaben. Deshalb heißt das Umschreiben einer Bauanleitung aus einer DNA-Sequenz in eine RNA-Sequenz Transkription. Ein erheblicher Teil der Transkripte wird direkt als RNA-Enzyme, regulatorische RNAs, rRNA oder tRNAs gebraucht. Die übrigen Transkripte werden im Zellkern noch bearbeitet und verlassen dann als mRNAs durch die Kernporen den Zellkern in Richtung Cytoplasma.
Im Zytoplasma schwimmen die großen und kleinen Untereinheiten der Ribosomen herum. An eine mRNA bindet zunächst die kleine und danach auch die große Untereinheit eines Ribosoms. Ribosomen sind biologischen Nanomaschinen für die Protein-Synthese. In einem Translation genannten Prozess übersetzen Ribosom mit Hilfe der tRNAs die Nukleotidsequenz der mRNA in die Aminosäure-Sequenz eines Proteins, welches in diesem Fall das Genprodukt ist. Ein Übersetzungsprozess (Translation) ist notwendig, weil den 20 verschiedenen Aminosäuren der Eiweiße nur jeweils 4 Sorten von Nukleotiden in DNA und mRNA gegenüberstehen. Deshalb werden sogenannte Tripletts aus je 3 Nukleotiden benötigt, um eine Aminosäure zu codieren. Die sogenannte Codonsonne zeigt, welche Tripletts für welche Aminosäuren stehen.
Am Anfang (5'-Ende) der mRNA findet ein Ribosom eine Erkennungs-Nukleotidsequenz, die ihm mitteilt, ob das zu synthetisierende Protein im Cytoplasma bleiben, in eine Membran eingebaut oder aus der Zelle exportiert werden soll. Soll das neue Protein in der Zelle bleiben, wird es vom Ribosom einfach mitten im Zytoplasma produziert. Ansonsten wandert das Ribosom mit der mRNA zum endoplasmatischen Retikulum und synthetisiert das Protein in die Membran oder in den Innenraum des endoplasmatischen Retikulums hinein. Dabei muss die Reihenfolge der 4 Nukleotide der mRNA übersetzt werden in die Sequenz der 20 unterschiedlichen Aminosäuren (Aminosäuresequenz), aus denen ein Protein bestehen kann. Deshalb nennt man diesen Vorgang am Ribosom einfach Translation (Übersetzung). Im Folgenden werden die Transkription und die Translation genauer dargestellt.
Transkription
|
|---|
Die Bauanleitung heißt Gen und besteht aus einem Material namens DNA (Desoxyribonucleic Acid) oder auf Deutsch DNS für Desoxyribonukleinsäure. Seine Informationen stecken in der Reihenfolge (Sequenz) der Desoxyribonukleotide genannten Monomere der DNA. Meistens vor den codierenden gibt es in der DNA auch noch regulatorische Sequenzen. An ihnen binden Moleküle aus der eigenen und vielen anderen Zellen, welche die Transkription einzelner Bauanleitungen (Gene) fördern oder verhindern.
Benötigt eine eukaryotische Zelle eine bestimmte RNA oder eine Eiweiß-Sorte, dann werden im Zellkern Kopien des DNA-Abschnittes mit der entsprechenden Bauanleitung (codierende DNA-Sequenzen des Gens) gemacht.
Die Kopien bestehen nicht aus DNA, sondern aus der chemisch etwas anderen RNA, die auf Deutsch Ribonukleinsäure (RNA) heißt. Fachleute sprechen deshalb meistens nicht von Kopieren, sondern von Transkription (Umschreiben). Und weil die RNAs wie Boten die Bauanleitung aus dem Zellkern ins Cytoplasma transportieren, nennt man sie Boten-RNA oder kurz mRNA (messenger RNA). Nach der Bauanleitung einer mRNA werden im Cytoplasma oder ins endoplasmatischen Retikulum durch Ribosomen viele Proteine produziert. Ein Ribosom übersetzt (Translation) die Bauanleitung einer mRNA in die Aminosäure-Sequenz eines Proteins.
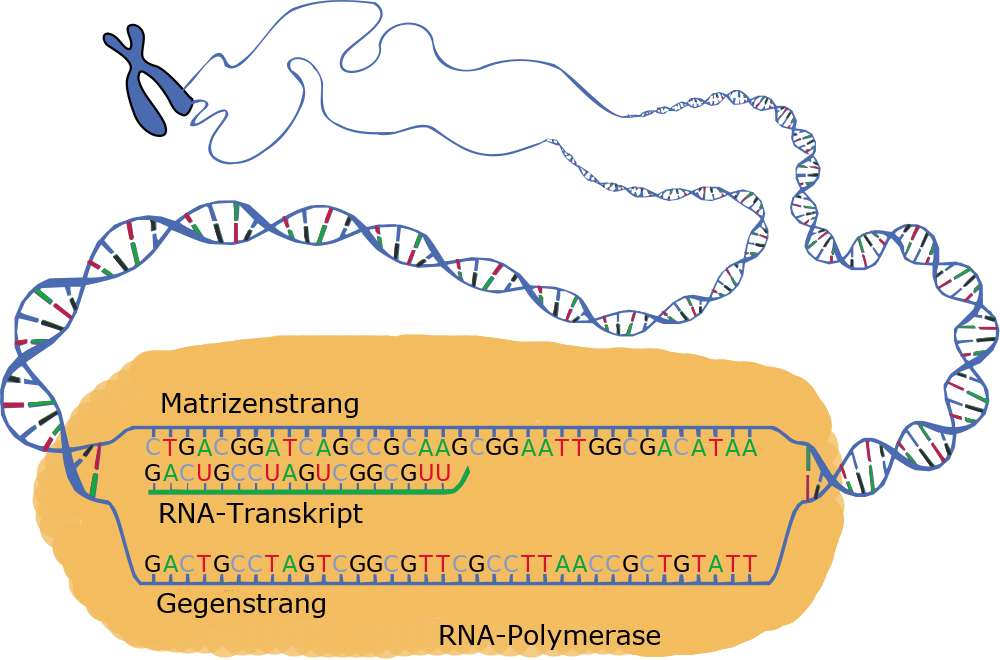
Damit ein Gen umgeschrieben werden kann, muss zunächst die DNA-Doppelhelix entspiralisiert und dann der DNA-Doppelstrang auf einer kurzen Strecke von 10-20 Nukleobasen so geöffnet werden, dass zwei DNA-Einzelstränge entstehen. An diesen beiden DNA-Einzelsträngen finden frei im Zellkern treibende RNA-Nukleotide passende Partner für Basenpaarungen. Aber nur an einem der beiden DNA-Einzelstränge verbindet der Enzym-Komplex DNA-abhängige RNA-Polymerase die über Wasserstoffbrückenbindungen gebundenen Nukleotide zu einem RNA-Transkript. Diesen als Vorlage für die RNA genutzten DNA-Einzelstrang nennt man DNA-Matrizenstrang.
Das folgende Schema zeigt, wie die beiden Stränge einer DNA-Doppelhelix durch eine RNA-Polymerase getrennt werden und an einem DNA-Strang eine RNA-Kopie entsteht.
| Schema der Transkription | |
|---|---|
 |
|
| Roland Heynkes, CC BY-SA-4.0. Ich habe nur die Größe der RNA-Polymerase korrigiert und ein Schema ins Deutsche übersetzt, das von einem anonymen Zeichner als public domain der Wikimedia zu Verfügung gestellt wurde. Das Schema der Transkription zeigt, wie sich der DNA-Doppelstrang öffnet und sich mit Hilfe des Enzyms RNA-Polymerase ein RNA-Gegenstrang bildet. Die Transkription beginnt am Promotor und endet am Terminator. | |
Nicht schön, aber Schritt für Schritt erklärt das folgende Schema, wie die Transkription funktioniert:
 |
|
| Roland Heynkes, CC BY-SA-4.0 | |
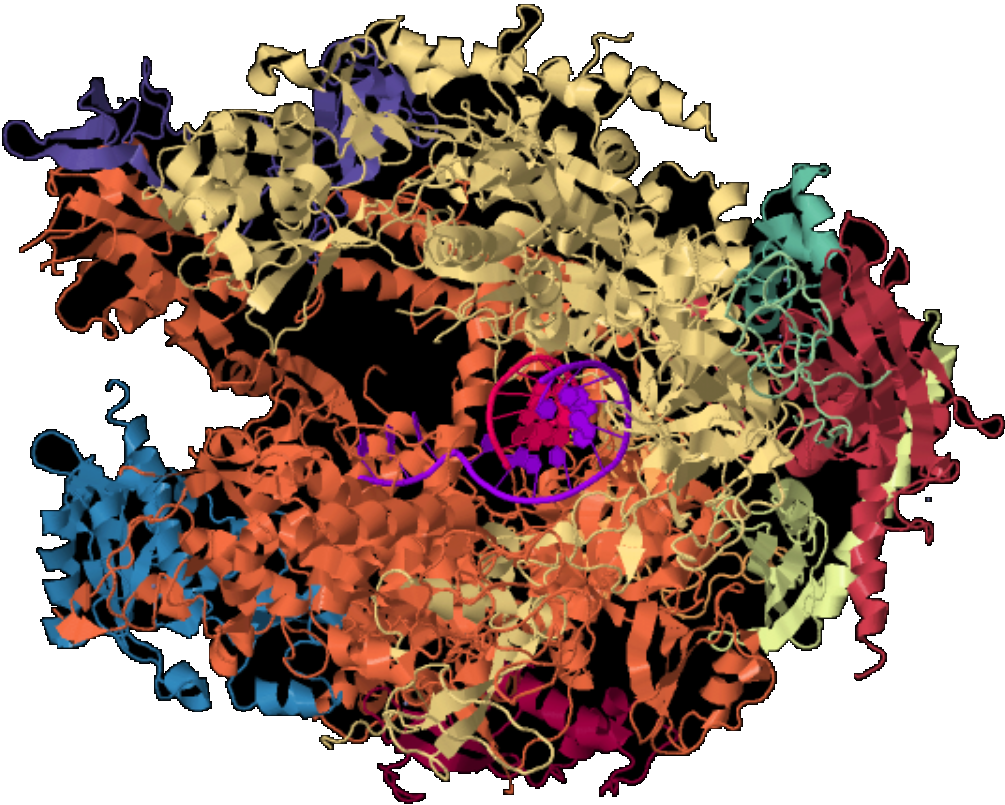
Die folgende Grafik zeigt einen RNA-Polymerase-II-Initiation-Complex mit 9 Nukleotiden RNA in der Cartoon-Darstellung.
| RNA-Polymerase-II-Initiation-Complex mit 9 Nukleotiden RNA (3S17) | |
|---|---|
 |
|
| Roland Heynkes, CC BY-NC-SA 4.0 | |
| Das einfach als screenshot in der Protein Data Bank produzierte Bild zeigt in unterschiedlichen Farben die verschiedenen Proteine des Enzym-Komplexes. Klickt man hier oder auf das Bild, dann kann man sich in einer 3D-Darstellung den Enzym-Komplex von allen Seiten und in verschiedenen Darstellungen ansehen. | |
Translation
|
|---|
Nach der Bauanleitung einer mRNA werden im Cytoplasma oder am endoplasmatischen Retikulum durch Ribosomen viele Proteine produziert. Ein Ribosom übersetzt (Translation) die Bauanleitung einer mRNA in die Aminosäure-Sequenz eines Proteins.
Der Sinn eines deutschen Satzes ergibt sich aus der Reihenfolge seiner Buchstaben. Genauso steckt auch der Informationsgehalt der Nukleinsäuren DNA und RNA in den Reihenfolgen (Sequenzen) ihrer Nukleobasen. Der gemeinte Sinn einer Buchstaben-Sequenz erschließt sich aber erst, wenn man weiß, wo die einzelnen Wörter beginnen und enden. So kann man beispielsweise aufgrund des fehlenden Leerzeichens nicht wissen, ob die Buchstaben-Sequenz: "kleineregel" kleiner Egel oder kleine Regel bedeuten soll. Beim alten deutschen Wort: "Wachstube" erschließt sich nur durch die Aussprache oder durch den Zusammenhang, ob es um eine Stube oder um eine Tube geht. Solche Interpretationshilfen gibt es bei DNA-Sequenzen nicht, aber dafür bestehen in ihr alle Wörter aus genau 3 Buchstaben, den sogenannten Tripletts. Meistens bezeichnet man diese Tripletts als Codons, weil sie etwas codieren. Jeweils 3 Basen stehen für (codieren) 1 von 20 verschiedenen Aminosäuren, aus denen unsere Proteine bestehen. Bestünden die Codons nur aus 2 Nukleotiden, dann gäbe es nur 4 mal 4 oder 4 hoch 2 mögliche und damit zu wenige Kombinationen. Die sogenannte Codonsonne zeigt von innen nach außen gelesen, welches Triplett für welche Aminosäure steht.
|
Codonsonne nennt |
 |
Das funktioniert aber nur, wenn klar ist, wo sich die Grenzen zwischen den Codons befinden. Aufgrund der immer gleichen Länge von 3 Nukleotiden ergeben sich glücklicherweise alle weiteren Codons, wenn man das die erste Aminosäure eines Proteins codierende Startcodon kennt. Und das ist kein Problem, weil das Startcodon in einer mRNA das die Aminosäure Methionin codierende Triplett AUG ist. Man kann sich daher den Beginn der Translation so vorstellen, dass ein Ribosom an einer mRNA entlang gleitet, bis es das Startcodon AUG gefunden hat.
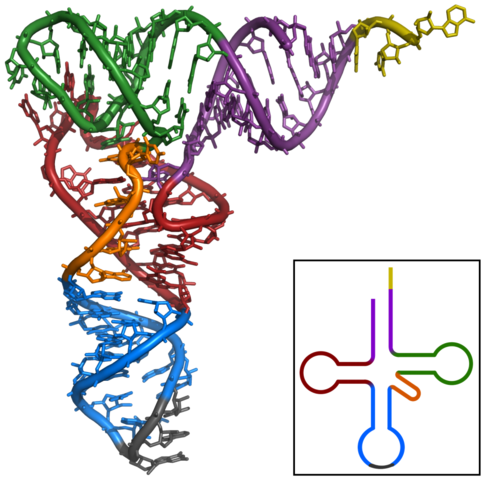
tRNA mit einem grauen Anticodon unten und einer gelbgrünen Andockstelle für eine Aminosäure rechts oben. |
 |
| anonym, CC BY-SA 3.0 |
| Auf einer Internetseite der internationalen Protein Data Base kann man ein dreidimensionales Modell einer tRNA unterschiedlich darstellen und von allen Seiten betrachten. |
| tRNA |
|---|
| Im großen Feld über diesem Text sind im WRL-Format aus der internationalen Protein Data Bank geladenen Koordinaten eingebunden. Sie können angezeigt und bewegt werden, wenn im Browser ein Plugin (Ergänzungsmodul) wie "Cosmo Player", "Cortona3D Viewer" oder "BS Contact" eingebunden ist. Es gibt auch spezielle Browser, die selbst WRL-Dateien anzeigen können. |
| Hier findet man eine langsamere, aber auch kompatiblere 3-D-Darstellung einer Hefe-tRNA mit dem JavaScript-Object JSmol und HTML 5. |
An das Startcodon bindet eine tRNA, an deren unterem Ende ein Anticodon genanntes Nukleobasen-Triplett (UAC) nach dem Schlüssel-Schloss-Prinzip perfekt zu dem Startcodon passt.
Hier geht es zu einer drehbaren 3-D-Darstellung einer Codon-Anticodon-Kontaktstelle mit dem JavaScript-Object JSmol und HTML 5.
Am oberen Ende der tRNA hängt die Aminosäure Methionin. Direkt daneben am Ribosom bindet an das folgende Codon eine weitere tRNA mit einem passenden Anticodon. Und wieder hängt oben an der tRNA die Aminosäure, die laut Codonsonne dem Codon in der mRNA entspricht.
| Translation an einem Ribosom |
|---|
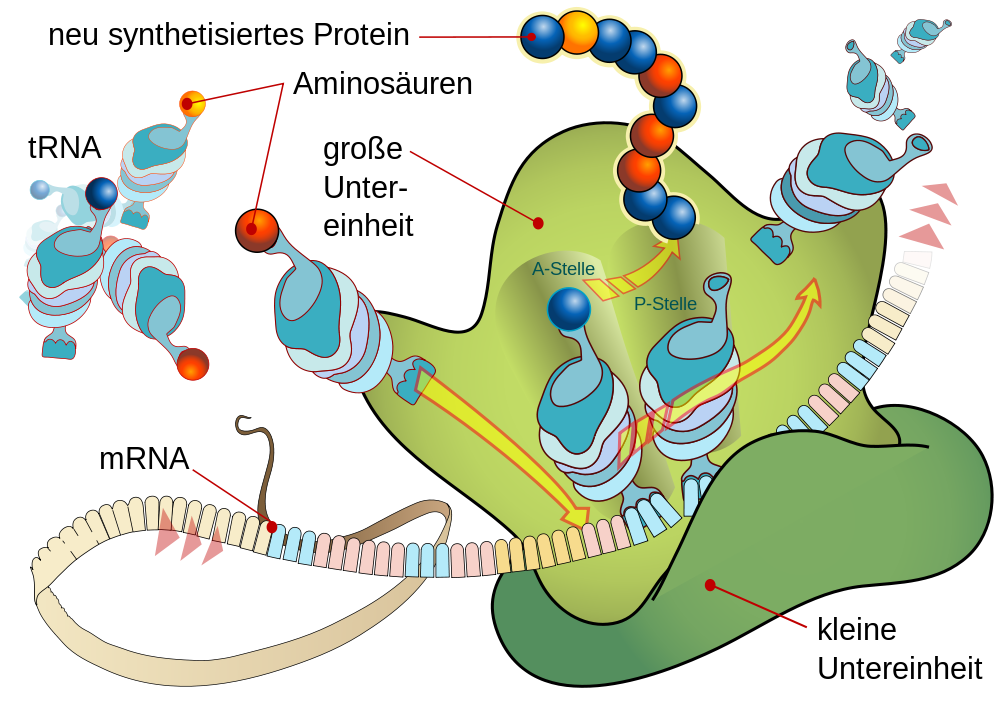 |
Dieses phantastische, von Matthias M. unter die Creative-Commons-Lizenz gestellte und damit kostenlos für unser Lernen verfügbare Schema der Translation erklärt im Grunde schon alles, was wir über die Translation wissen müssen. Eine tRNA nach der anderen versucht, am Ribosom mit ihrem aus 3 Nukleotiden bestehenden Anticodon an drei komplementäre Nucleotide der mRNA zu binden. Wenn ein Anticodon passt, dann wird die wachsende Aminosäurekette an die Aminosäure angehängt, die oben an der tRNA hängt. |
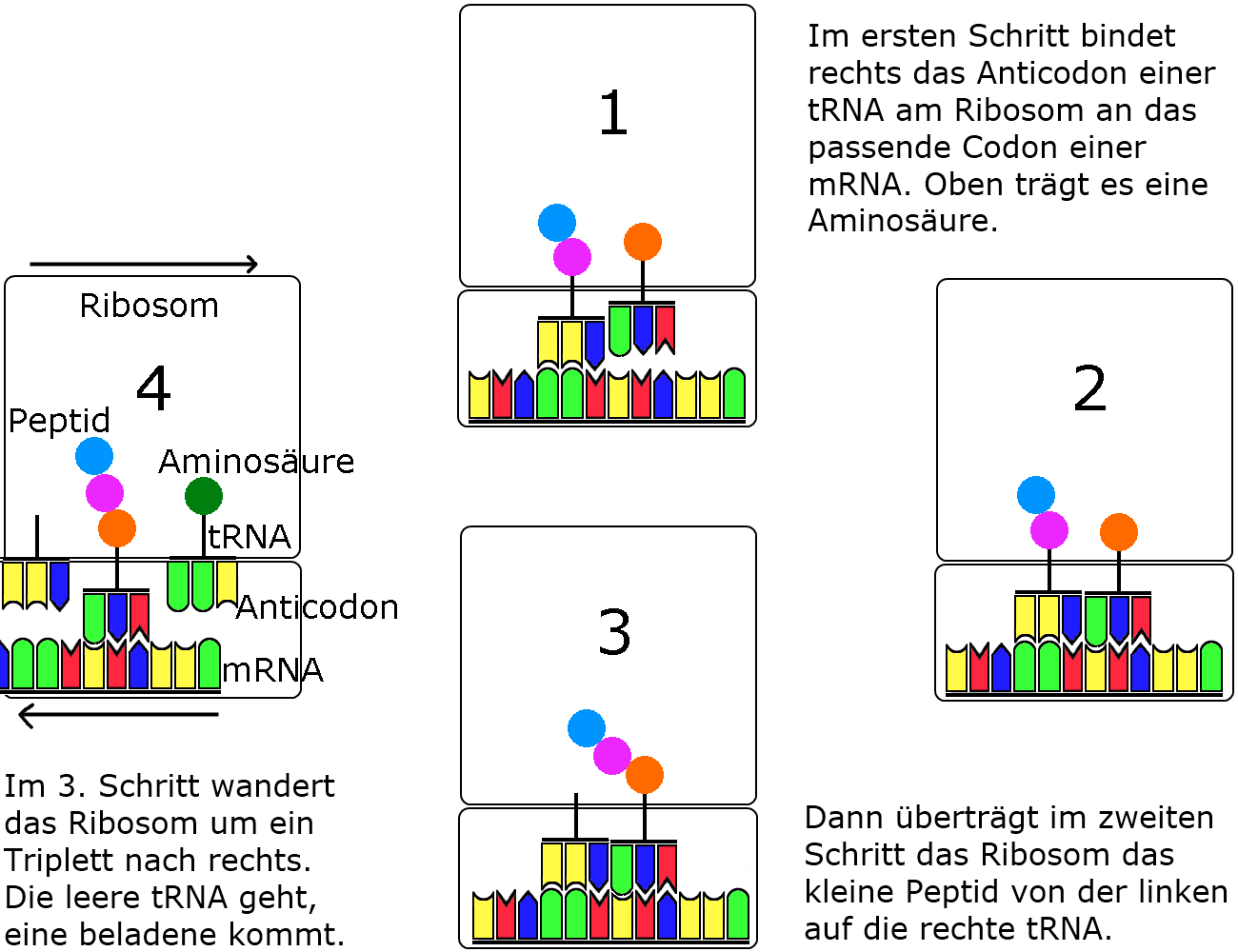
Ohne strukturelle Details konzentriert sich mein folgendes Schema auf die schrittweise Darstellung der Vorgänge in einem Zyklus.
mein einfaches Kreislaufschema der Translation
|
|---|
 |
|
| Dieses Schema der Translation habe ich selbst gezeichnet. Es soll das Verständnis der Translation erleichtern, indem es das Anhängen einer Aminosäure als Kreislauf zeigt und dabei auch nachvollziehbar macht, wie dabei das Ribosom um 1 Triplett an der mRNA entlang wandert. Die tRNAs werden ganz auf das Anticodon und die Aminosäure-Bindungsstelle reduziert dargestellt, um die Sache übersichtlich zu halten. | |
Wie in den beiden Schemata gezeigt, hängt das Ribosom immer wieder das bereits produzierte Peptid an die nächste Aminosäure, bis die Translation mit einem Stoppcodon endet.
|
|
|---|
.
Kommentare und Kritik von Fachleuten, Lernenden und deren Eltern sind jederzeit willkommen.
Roland Heynkes, CC BY-SA-3.0 DE

{kind=link}
{kind=link}
{kind=link}