
Schulbuch-unabhängiger Selbstlern-Hypertext Genetik
Roland Heynkes 13.5.2024, CC BY-SA-4.0 DE
If you cannot read German-language texts, you could try a translation into your native language with DeepL.
Dieser Selbstlern-Hypertext versucht verständlich zu erklären, was laut Lehrplänen und Schulbüchern in Schulen über Genetik gelernt werden soll. Inhaltlich habe ich mich allerdings an richtigen Fachbüchern, naturwissenschaftlichen Dokumentationen und naturwissenschaftlicher Primärliteratur orientiert. Was davon glaubwürdig und korrekt ist, versuche ich aufgrund meiner Fachkompetenz als Diplombiologe mit den Hauptfächern Genetik, Biochemie und organische Chemie zu beurteilen. Zur Veranschaulichung nutze ich mit Creative-Commons-Lizenzen oder als Pulic Domain freigegebene grafische Darstellungen oder stelle selbst her, was ich im World Wide Web nicht finde.
Manches wird im Text mehrfach wiederholt, um es im Gedächtnis zu verankern. In Abhängigkeit von Schulform, Jahrgangsstufe und persönlichem Interesse brauchen Schüler (männlich, weiblich, divers) aber nicht jeden in diesem Selbstlern-Hypertext verwendeten Fachbegriff und nicht jedes Kapitel. Möge sich jedes Individuum heraus picken, was es braucht oder interessiert.
|
Für erfolgreiches Lösen der Aufgaben zu Material in Klausuren und zur effektiven Vorbereitung darauf mit diesem Selbstlern-Hypertext:
|
Zu diesem Selbstlern-Hypertext habe ich ein kleines "Arbeitsblatt" mit Aufgaben erstellt.
In der menschlichen Arbeitswelt werden Baupläne verwendet, wenn wir komplizierte Dinge bauen. In der Küche benutzen wir Rezepte, wenn wir komplizierte Kuchen backen. Und selbst die einfachsten Lebewesen sind komplizierter als alles, was Menschen bauen oder kochen. Deshalb brauchen auch Lebewesen in ihren Zellen Baupläne, damit sie selbst herstellen können, was sie zum leben, wachsen und vermehren brauchen.
Lebewesen sind extrem komplexe, offene Systeme, in denen sehr viele Sorten von Biomolekülen zeitlich, räumlich und funktionell exakt koordiniert zusammen arbeiten. Tiere und Pilze nehmen einige (essenzielle) dieser Biomoleküle mit der Nahrung auf. Alle Lebewesen stellen aber zumindest die meisten ihrer Biomoleküle mit Hilfe von Enzymen selbst her. Enzyme sind Biokatalysatoren, also von Lebewesen produzierte Katalysatoren. Und für die Produktion ihrer eigenen Enzyme und aller anderen Proteine und Nukleinsäuren benötigen Lebewesen Baupläne, Bauanleitungen oder Rezepte.
| Biomoleküle sind hauptsächlich aus Kohlenstoff und Wasserstoff bestehende, von Lebewesen produzierte Moleküle. |
Umgangssprachlich sprechen wir von einem Bauplan, wenn wir die Bauanleitung für ein einzelndes Protein oder eine RNA meinen. Bauplan nennen wir aber auch die Summe aller Bauanleitungen, die gemeinam den Bauplan für den gesamten Organismus darstellen. Um zwischen diesen beiden Ebenen leichter unterscheiden zu können, haben wir in der Biologie die Fachbegriffe Gen für die einzelne Bauanleitung und Genom für die Summe aller Bauanleitungen.
| Aufgaben zur Erarbeitung des Lernstoffes bzw. zur Lernkontrolle | |
|---|---|
| a1 | Nenne die Biomoleküle, die wir nicht ohne Bauplan herstellen können! |
| a2 | Nenne den Sammelnamen der Grundbausteine unserer Proteine und wieviele unterschiedliche es davon gibt! |
| a3 | Nenne die Information, die das Gen genannte Rezept für ein Protein enthält! |
| Hier geht es zu den Antworten. | |
Alle Lebewesen bestehen aus mindestens einer Zelle. Und Zellen bestehen aus Wasser, Mineralstoffen und Biomolekülen. Mineralstoffe und manche Biomoleküle müssen mit der Nahrung aufgenommen werden (z.B.: Vitamine sowie essentielle Aminosäuren und Fettsäuren). Wasser entsteht in Zellen auch als eine Art Abfallstoff. Aber die meisten Biomoleküle müssen von unseren Zellen gezielt hergestellt werden. Die bekanntesten Biomoleküle sind Vitamine, Fette und andere Lipide, Zucker und größere Kohlenhydrate, Nukleinsäuren sowie Eiweiße. Viele Eiweiße und manche Nukleinsäuren sind Enzyme genannte Werkzeuge, die Vitamine, Lipide oder Kohlenhydrate herstellen können. Sie brauchen dafür keine Anleitung, sondern ein Enzym beschleunigt und steuert (katalysiert) einfach aufgrund seiner besonderen Form eine bestimmte chemische Reaktion, die für die Produktion eines Biomoleküls erforderlich ist. Baupläne benötigen Lebewesen nur für die Produktion von Nukleinsäuren und Eiweißen (Proteinen).
Proteine sind lange Ketten aus 21 unterschiedlichen Aminosäuren (Die 20 schon länger von der Codonsonne bekannten und Selenocystein, das nicht wie die anderen durch eines der Codons/Tripletts codiert wird, sondern durch ein Stoppcodon in einer bestimmten Umgebung). So wie wir mit nur 30 Buchstaben unzählige Wörter bilden können, so können auch unzählige unterschiedliche Proteine aus nur 21 verschiedenen Aminosäuren gebildet werden. Entscheidend ist in beiden Fällen die Reihenfolge (Sequenz) der Buchstaben eines Wortes bzw. der Aminosäuren eines Proteins. Die richtigen Reihenfolgen der Buchstaben unserer Wörter lernen wir mühsam in der Schule. Unsere Zellen haben für jedes ihrer Eiweiße ein Rezept (Gen), in dem die richtige Reihenfolge der Aminosäuren aufgeschrieben ist. Alle diese Rezepte für Eiweiße haben wir von unseren Eltern geerbt. Und viele Unterschiede zwischen verschiedenen Menschen oder zwischen Menschen und Schimpansen beruhen darauf, dass ein Teil ihrer Proteine an manchen Positionen ihrer Aminosäureketten (Aminosäuresequenzen) unterschiedliche Aminosäuren eingebaut haben. Andere Unterschiede beruhen darauf, dass verschiedene Individuen oder Spezies unterschiedlich viel von bestimmten Proteinen produzieren.
Interessierte finden zu Biomolekülen mehr Informationen im Lerntext Biomoleküle.
Die Genetik erklärt, wie Gene die Formen und Funktionen der Proteine beeinflussen und auf diesem Wege die Eigenschaften eines Lebewesens.
Was ein Lebewesen als Individuum ausmacht, das sind sein Bauplan und die Gesamtheit aller Informationen, die auf vielen Ebenen in seinen Strukturen stecken. Denn biologische Informationen können viel dauerhafter als ihre Informationsträger (Strukturen) sein und Strukturen viel unveränderlicher als Zusammensetzung ihrer Bestandteile. Während ein Individuum immer das selbe bleibt, ist es schon am nächsten Tag nicht mehr das gleiche. Denn in jeder Sekunde unseres Lebens sterben in uns unzählige Zellen und ungefähr ebenso viele entstehen. Gleichzeitig tauschen wie ständig die Atome aus, aus denen wir bestehen. Wir nehmen sie mit der Nahrung auf, bauen sie durch unseren Stoffwechsel in unsere Biomoleküle ein und scheiden dafür verbrauchte Biomoleküle aus.
Was ein Lebewesen wirklich ausmacht, sind daher nicht seine Atome und Moleküle, sondern die in ihm steckenden Informationen. So stecken beispielsweise unsere Gedächtnisinhalte in Strukturen und Verknüpfungen von Nervenzellen. Und obwohl bei jeder Zellteilung die Hälfte aller Atome in der DNA im Zellkern einer Zelle ersetzt wird, bleiben die in den DNA-Sequenzen (Nukleotid-Reihenfolgen) steckenden Informationen lebenslang nahezu unverändert erhalten. Diese von unseren Eltern ererbten Baupläne (Genome) sind gigantische Rezeptbücher mit Zigtausenden Rezepten (Genen) für Proteine (Eiweiße) und RNAs.
Die folgende Tabelle soll die wichtigsten Fachbegriffe im Zusammenhang mit den Biopolymeren übersichtlich zusammenfassen.
| wichtige Biopolymere und ihre Monomere (Bausteine) | |||||
|---|---|---|---|---|---|
| Biopolymer-Typ | Monomer (eins) | Dimer (zwei) | Oligomer (mehrere) | Polymer (viele) | |
| Peptide | Aminosäure | Dipeptid | Oligopeptid | Polypeptid (Protein) | |
| Kohlenhydrate | Monosaccharid (Einfachzucker) z.B. Glucose | Disaccharid (Zweifachzucker) z.B. Maltose | Oligosaccharid (Mehrfachzucker) z.B. Raffinosen | Polysaccharid (Vielfachzucker) z.B. Stärke | |
| Erbmaterial | Nukleotid | Dinukleotid (z.B. NAD) | Oligonukleotid | Nukleinsäuren (DNA oder RNA) | |
Wie die in der Tabelle erwähnten Monomere und Lipide aussehen, zeigt der Lerntext Biomoleküle.
Wir verwenden traditionell Papier, um auf diesem organischen Material als Informationsträger mit Stiften Informationen aufzuschreiben oder zu zeichnen. Der ebenfalls aus organischem Material bestehende Informationsträger in unseren Zellen ist die DNA. DNA und Proteine sowie die großen RNAs und Kohlenhydrate sind Makromoleküle, weil jedes ihrer Moleküle aus weit mehr als 1000 Atomen besteht. Und sie sind Polymere, weil sie aus vielen kleinen Grundbausteinen, den sogenannten Monomeren aufgebaut sind. Poly bedeutet viele und Mono bedeutet 1. Biopolymere heißen sie, weil sie von Lebewesen produziert werden. Im Gegensatz zu chemisch hergestellten Polymeren bestehen die Biopolymere Nukleinsäuren und Proteine aus unterschiedlichen Monomeren. Die Reihenfolge (Sequenz) der Monomere beeinflusst die Eigenschaften der Biopolymere.
| Monomere, Oligomere und Polymere | |
|---|---|
 |
Monomer nennt man einen Baustein, eine Untereinheit oder eine Perle, die eine lange Kette bildet. Beispiele für Monomere unter den Biomolekülen sind Aminosäuren und Nukleotide. Oligomer nennt man eine kurze Kette aus mehreren Monomeren. Beispiele dafür sind Oligonukleotide und die Peptide, die beispielsweise bei der Vorverdauung von Proteinen im Magen entstehen. Polymer nennt man eine lange Kette aus vielen Monomeren. Beispiele sind Ketten aus vielen Perlen, Proteine aus vielen Aminosäuren oder Nukleinsäuren (DNA oder RNA) aus vielen Nukleotiden. |
| Roland Heynkes, CC BY-SA-4.0 | |
Die Bedeutung (Information) eines Wortes steckt nicht in Informationsträgern wie Papier und Tinte oder in seinen Buchstaben, sondern in der Reihenfolge (Sequenz) der Buchstaben auf dem Papier. Die Bedeutung eines Wortes kann durch einen Tippfehler komplett verändert werden (z.B.: Mund zu Hund oder Fund). Darum ist die genaue Sequenz (Reihenfolge) der Buchstaben entscheidend. Genauso wichtig ist für die Zellen aller Lebewesen die Reihenfolge der Monomere in ihren Biopolymeren. Sie muss bei Nukleinsäuren, Proteinen und vielen Kohlenhydraten exakt eingehalten werden, damit diese Biopolymere ihre Aufgaben erfüllen können. Die Reihenfolge der Zucker-Monomere in einem komplexen Kohlenhydrat wird durch Enzyme bestimmt. Die Nukleotidsequenzen unserer Nukleinsäuren werden vererbt. Und die Aminosäuresequenzen der Proteine werden durch Nukleotidsequenzen von Nukleinsäuren bestimmt.
| Aufgaben zur Erarbeitung des Lernstoffes bzw. zur Lernkontrolle | |
|---|---|
| a4 | Beschreibe mit einem Satz, worin die in der DNA gespeicherte Information steckt! |
| a5 | Erkläre, wie die DNA mit nur 4 unterschiedlichen Nukleotiden 20 unterschiedliche Aminosäuren codieren kann! |
| Hier geht es zu den Antworten. | |
Damit ein Gen die Eigenschaften eines Proteins festlegen kann, muss es die Aminosäuresequenz des Proteins bestimmen. Dazu muss das Gen Informationen enthalten. Schauen wir uns genauer an, wie ein Gen eine Aminosäuresequenz codiert. Gespeichert ist die Information eines Gens in einem Material namens DNA.
| animiertes Schema der DNA-Doppelhelix |
|---|
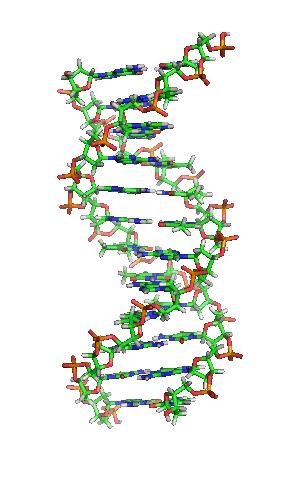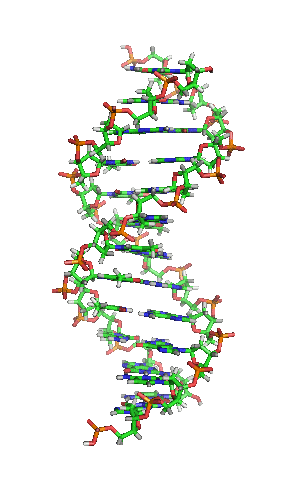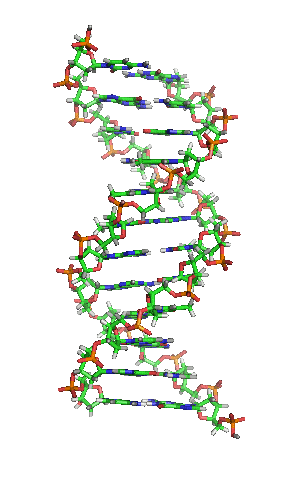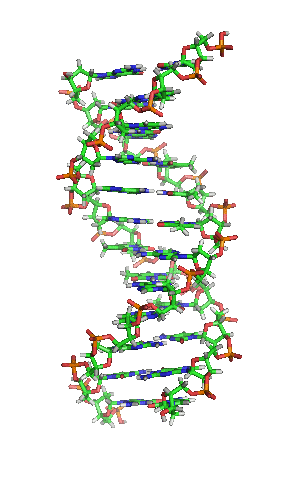
|
| Richard Wheeler, CC BY-SA 3.0 |
| Die Animation erschwert zwar die genaue Betrachtung, vermittelt dafür aber ein intuitives Gefühl für die Struktur der DNA-Doppelhelix. Dabei hilft die Farbcodierung. Kohlenstoff-Atome sind grün dargestellt, Stickstoff blau, Sauerstoff rot, Phosphor orange und Wasserstoff grau. Dadurch wirken im DNA-Rückrat Desoxyribose grünorange und Phosphat rotorange, während dazwischen die Nukleobasen blaugrün gesprenkelt aussehen. |
Aber DNA ist nur der Datenträger, vergleichbar mit einer CD, einem Speicherchip, einer Festplatte oder dem Papier und der Druckerfarbe eines Buches. Genetische Informationen (Erbinformationen) stecken nicht einfach im Material des Biopolymers DNA oder in deren Nukleotide (genauer: Desoxyribonukleotide) genannten Monomeren. Weil Nukleinsäuren und Proteine im Gegensatz zu Kohlenhydraten unverzweigt sind, steckt bei ihnen die Information in der Sequenz der Monomere. Die Erbinformationen stecken in den Sequenzen der DNA-Nukleotide.
Das funktioniert wie bei unseren Wörtern. Die Reihenfolge der Buchstaben bestimmt den Sinn eines Wortes. Auch Gene enthalten so etwas wie Buchstaben. Es sind die Nukleotide genannten Grundbausteine der Nukleinsäuren DNA und RNA, deren Namen man mit A, C, G und T abkürzt. Die Nukleotidsequenz genannte Reihenfolge der Nukleotide enthält die Information(en) eines Gens. Nukleotidsequenzen der DNA bestimmen (codieren) die Aminosäuresequenzen der Proteine. Die DNA ist allerdings eher mit einem ganzen Buch als mit einem Wort zu vergleichen, weil die Nukleotidsequenz jedes DNA-Moleküls mehrere bis Tausende Rezepte (Gene) für die Herstellung von Eiweißen (Proteinen) oder RNAs enthält.
Menschliche Sprachen haben viele Buchstaben, aber digital speichern wir Texte, Bilder und Filme mit nur 2 unterschiedlichen Zuständen wie 0 und 1, An oder Aus, Loch oder kein Loch. Es gibt in den Nukleinsäuren DNA und RNA jeweils 4 unterschiedliche Sorten von Nukleotiden. Unsere Erbinformationen mit den Bauanleitungen für alle unsere RNAs und Proteine sind also aufgeschrieben (codiert) in der DNA mit einem Alphabet aus nur 4 Buchstaben. Prinzipiell reichen 4 Buchstaben für die Codierung der Aminosäure-Sequenz eines Proteins durch die Nukleotid-Sequenz einer Nukleinsäure. Allerdings stehen die nur 4 Sorten von Nukleotiden als Monomere der DNA der deutlich größeren Anzahl von 20 unterschiedlichen Aminosäuren als Monomere menschlicher Proteine gegenüber. Um 20 verschiedene Aminosäuren mit nur 4 unterschiedlichen Nukleotiden codieren zu können, müssen jeweils 3 Nukleotide zu einem Codon zusammengefasst werden, denn Codons aus nur 2 Nukleotiden könnten nur 4x4=16 verschiedene Aminosäuren codieren.
Also bilden immer 3 Nukleotide eine Art Wort (Codon), das für eine bestimmte Aminosäure steht. Und an den Ribosomen wird die Nukleotidsequenz des Gens übersetzt in die Aminosäuresequenz des Proteins. Das folgende Schema soll das Prinzip veranschaulichen. Immer 3 benachbarte Nukleotide (Triplett) in der oberen Zeile werden übersetzt in eine Aminosäure in der unteren Reihe. Das folgende Schema soll leichter nachvollziehbar machen, wie Aminosäuresequenzen durch Nukleotidsequenzen in DNA codiert werden.
| Gene codieren Proteine |
|---|
 |
Ebenfalls in die DNA geschriebene regulatorische Sequenzen binden Botenstoffe aus der eigenen und vielen anderen Zellen, welche das Kopieren einzelner Bauanleitungen (Gene) fördern oder verhindern.
| Aufgaben zur Erarbeitung des Lernstoffes bzw. zur Lernkontrolle | |
|---|---|
| a6 | Erkläre, warum Lebewesen nicht ohne Proteine auskommen! |
| a7 | Beschreibe den Zusammenhang zwischen den Proteinen und den Eigenschaften eines Lebewesens! |
| a8 | Erkläre Schritt für Schritt, wie der Bauplan (das Genom) die Eigenschaften eines Lebewesens beeinflusst! |
| Hier geht es zu den Antworten. | |
Was Menschen voneinander und von anderen Spezies unterscheidet, sind die Eiweiße. In der Fachsprache nennen wir sie Proteine, damit man sie nicht mit dem Eiweiß im Ei eines Huhns verwechselt. Ohne Proteine könnte sich in einem Lebewesen nichts bewegen. Es könnte nichts wahrnehmen und auf nichts reagieren. Proteine ermöglichen und steuern fast alle chemischen Reaktionen in einem Lebewesen. Und ohne Proteine würde jede Zelle sofort zerfallen. Proteine sind die wichtigsten Bausteine und die eigentlichen Akteure in jedem Lebewesen.
Die Eigenschaften eines Lebewesens hängen überwiegend davon ab, wann, in welchen Mengen und in welchen Zellen es welche Proteine produziert und welche Formen diese Proteine haben. Denn die Form eines Proteins bestimmt seine Funktion und die Funktionen seiner Proteine bestimmen die Eigenschaften eines Lebewesens.
Wird in einem Protein auch nur eine von Hunderten Aminosäuren gegen eine etwas andere ausgetauscht, dann führt das normalerweise dazu, dass das Protein eine zumindest etwas andere Form annimmt. Und jede Veränderung der Form verändert auch die Eigenschaften eines Proteins. Meistens kann es dann etwas besser oder schlechter. Manchmal erlangt ein Protein dadurch sogar eine neue Fähigkeit. Und mit den Eigenschaften ihrer Proteine ändern sich auch die Eigenschaften der Lebewesen. Darum ist es extrem wichtig, dass die exakten Reihenfolgen (Sequenzen) aller Aminosäuren in sämtlichen Proteinen eines Lebewesens genau festgelegt sind. Und genau das leistet der Bauplan (das Genom) eines Lebewesens.
Proteine sind lange, unverzweigte Ketten aus Aminosäuren, von denen es in unseren Zellen 21 unterschiedliche gibt.
| die 20 normal codierten Aminosäuren menschlicher Proteine |
|---|
 |
| anonym, public domain |
Die Begriffe Primärstruktur, Sekundärstruktur, Alpha-Helix, Betafaltblatt, Tertiärstruktur und Quartärstruktur gehen über Euer Schulbuch hinaus. Sie erleichtern aber hier das Verständnis der Protein-Faltung.
Aus Aminosäureketten entstehen Proteine:
| Das schrittweise Entstehen der räumlichen Form eines Proteins |
|---|
 |
| Mariana Ruiz Villarreal, Beschriftung von mir, public domain |
| So ergibt sich aus der Aminosäuresequenz die räumliche Form eines Proteins. Die Form bestimmt die Eigenschaften und damit auch die Funktionen eines Proteins. Und die Funktionen unserer Proteine bestimmen unsere Eigenschaften. |
| rotierendes Protein (Clostridium perfringens Alpha Toxin) |
|---|
 |
| Ramin Herati, public domain |
Das Problem dabei ist, dass es nahezu unendlich viele mögliche Reihenfolgen (Sequenzen) gibt, wenn Hunderte Aminosäuren ein Protein bilden und für jede Position der Aminosäure-Sequenz 21 unterschiedliche Aminosäuren zur Auswahl stehen. Damit eine Zelle von den praktisch unendlich vielen möglichen immer genau die richtige Aminosäurekette produziert, braucht sie für jedes seiner Proteine einen Bauplan. Solch einen Bauplan nennt man Gen. Es gibt im Prinzip für jedes Protein ein Gen, welches die Aminosäuresequenz des Proteins bestimmt. Und die Summe aller Gene nennt man das Genom eines Lebewesens.
| rotierendes Protein (AMPA-Rezeptor) |
|---|
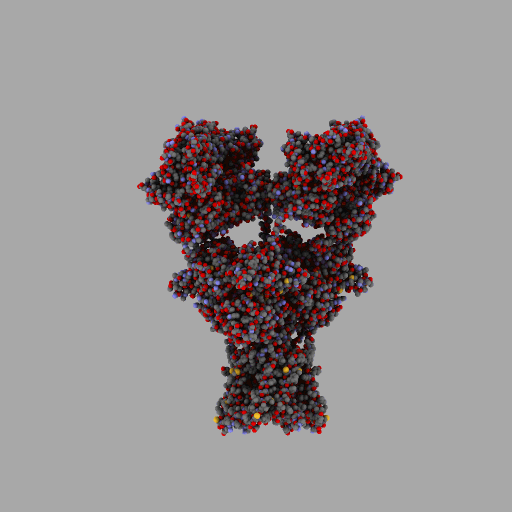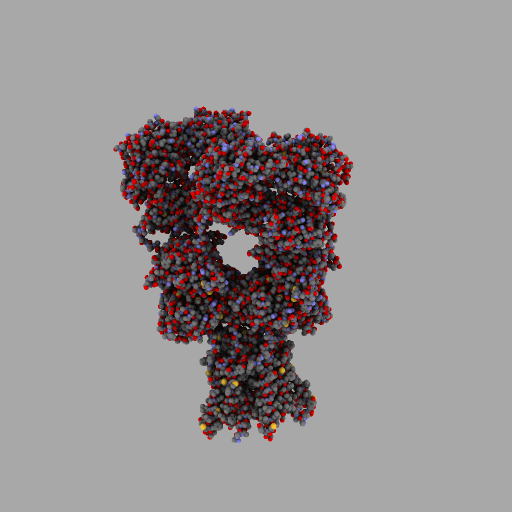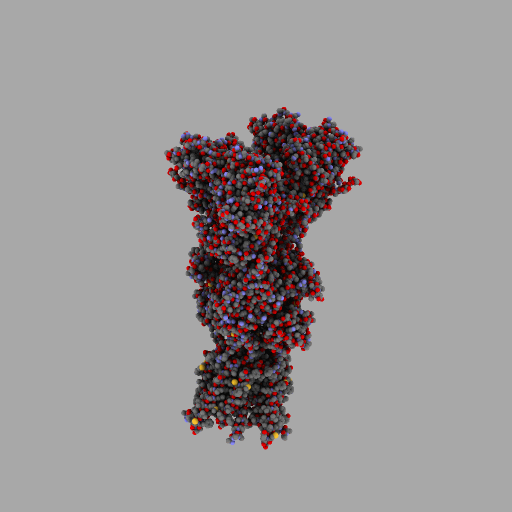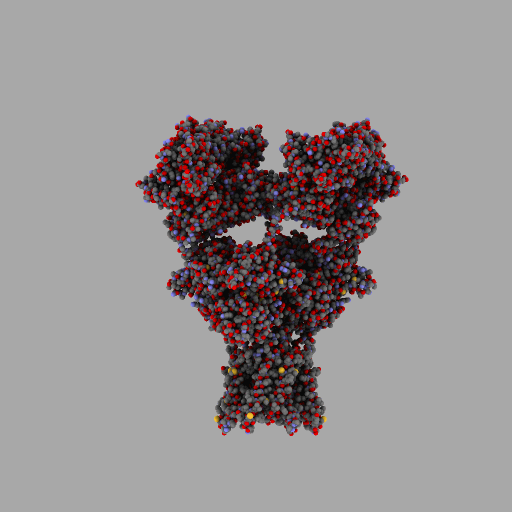 |
| anonym, CC BY-SA 3.0 |
Entscheidend für die Eigenschaften jedes Lebewesens und jede seiner Zellen ist also, wann, für wie lange und wie stark seine Gene aktiviert werden und welche Aminosäuresequenzen sie codieren.
| Aufgabe zur Erarbeitung des Lernstoffes bzw. zur Lernkontrolle | |
|---|---|
| a9 | Erkläre die Abkürzung mRNA! |
| Hier geht es zur Antwort. | |
Das Genom eines Lebewesens enthält für jedes seiner Proteine ein Rezept (Gen), in dem die Aminosäuresequenz des Proteins aufgeschrieben ist. Ähnlich wie Rezepte für Kuchen und Kekse stehen auch die Rezepte für Eiweiße hintereinander in Kochbüchern. Allerdings nennt man in Zellen die Rezepte Gene und die Kochbücher Chromosomen.
Wenn Zellen bestimmte Eiweiße brauchen, machen sie Kopien von den Genen (Rezepten). Diese Rezept-Kopien kommen wie Botschaften oder Boten zu winzigen Maschinen, die man Ribosomen nennt. Und weil diese Boten aus dem Material RNA bestehen, nennt man sie Boten-RNAs. Auf Englisch heißt Bote Messenger. Abgekürzt nennen wir deshalb die Rezept-Kopien mRNAs. Mit Hilfe solcher mRNAs stellen Ribosomen alle Eiweiße her, welche die Zelle braucht.
| Ribosomen-Untereinheiten | |
|---|---|
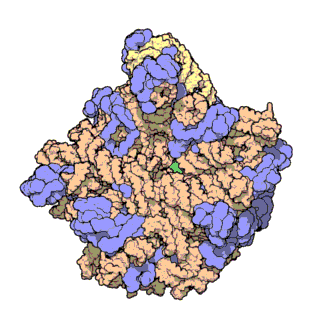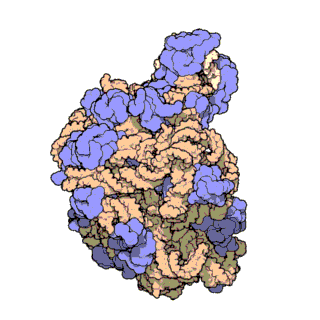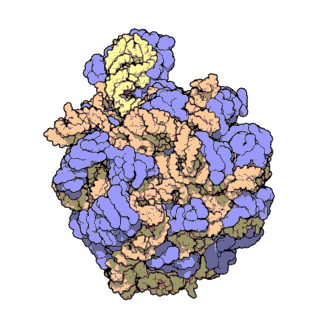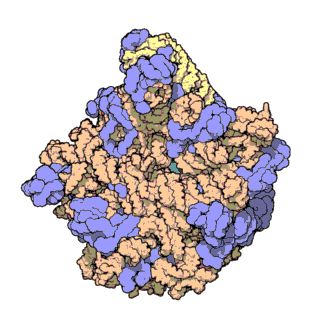 |
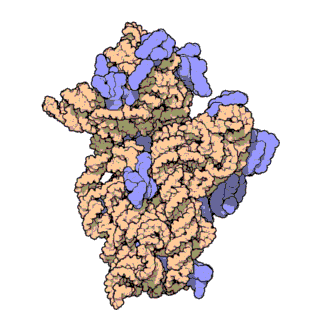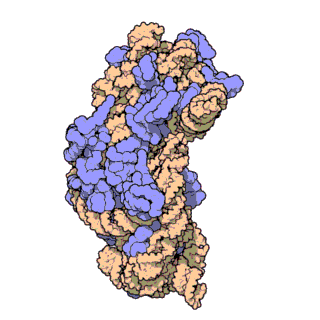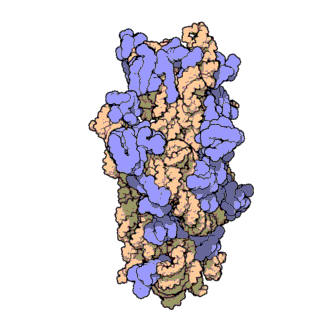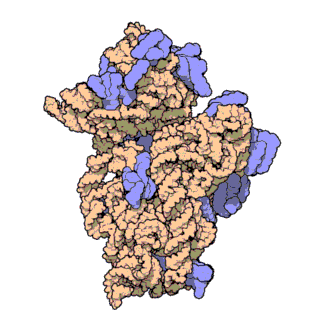 |
| Diese animierten GIF zeigen links die große und rechts die kleine Ribosomen-Untereinheit. | |
| Protein Data Bank Educational Resources | |
Lernkasten Baupläne für Proteine
|
| Aufgaben zur Erarbeitung des Lernstoffes bzw. zur Lernkontrolle | |
|---|---|
| b1 | Nenne mit einem Satz, was die mehr als 200 menschlichen Zelltypen gemeinsam haben! |
| b2 | Erkläre, warum unsere Zellen trotzdem so unterschiedlich sind! |
| Hier geht es zu den Antworten. | |
Menschen bestehen aus ungefähr 30 Billionen (30.000.000.000.000) menschlichen Zellen. Wir könnten allerdings nicht überleben, wenn nicht in und auf uns noch etwas mehr Bakterien und unzählige Viren existieren würden.
Es gibt in uns mehr als 200 unterschiedliche menschliche Zellarten. Besonders bekannt sind rote und weiße Blutzellen, kugelige Eizellen, lange Muskelzellen, verzweigte Nervenzellen und nahezu unsterbliche Stammzellen.
Trotzdem haben alle diese sehr unterschiedlichen Zelltypen eines Menschen praktisch den selben Bauplan.
| Die folgenden Bilder zeigen verschiedene Blutzellen (Blutkörperchen) mit ungefähr richtigen Größenverhältnissen. |

|
| Blutplättchen heißen Thrombozyten, rote Blutkörperchen heißen Erythrozyten. Alle anderen hier gezeigten Blutzellen gehören zu den weißen Blutkörperchen (Leukozyten). |
Jedes Eiweiß erfüllt eine bestimmte Aufgabe in der Zelle. Viele Eiweiße sind Bausteine, aus denen Zellen bestehen. Andere Eiweiße stellen Kohlenhydrate oder Lipide her, aus denen Zellen bestehen. Deshalb hängen die Eigenschaften einer Zelle davon ab, aus welchen Eiweißen sie besteht.
Von den Kochbüchern (Chromosomen) hängt ab, welche Eiweiße eine Zelle herstellen kann. Aber die Zellen entscheiden, welche Rezepte (Gene) aus den Kochbüchern (Chromosomen) sie benutzen. So können unsere Zellen entscheiden, ob sie Nervenzellen oder Muskelzellen sein wollen. Aber normalerweise hören sie auf ihre Nachbarn und werden die Zellen, die gebraucht werden.
Das Kapitel: "Der Aufbau einer tierischen Zelle" im "Lerntext Organellen" zeigt den Zellkern und andere wichtige Organellen einer tierischen Zelle.
Informationen zu den Strukturen und Funktionen von Zellkern (Nukleus) und Nukleoli sowie zu den Kernporen findet man im Kapitel Zellkerne als Bibliotheken eukaryotischer Zellen des Lerntextes Organellen.
| Löse ausschließlich mit Hilfe des Lerntext-Kapitels Zellkerne als Bibliotheken eukaryotischer Zellen die Aufgaben des Lernmoduls Zellkerne als Bibliotheken eukaryotischer Zellen! |
Nützlich für das Verständnis der Rolle des Zellkerns ist eine genauere Betrachtung der Metamorphose.
| Löse ausschließlich mit Hilfe meiner kritischen Zusammenfassung der Fernsehdokumentation Metamorphose die Aufgaben des Lernmoduls Metamorphose! |
| Löse ausschließlich mit Hilfe der folgenden 5 Kapitel die Aufgaben des Lernmoduls Chromosomen! |
Jeder der beiden Baupläne im Zellkern einer menschlichen Zelle ist etwa so lang wie ein Mensch und wäre damit so unhandlich wie ein zwei Meter dickes Lexikon. Als lange vor Wikipedia große Lexika wie der Brockhaus oder die Encyclopædia Britannica mit Zigtausend Seiten zu dick und unhandlich wurden, da teilte man sie auf in mehrere kleinere Bücher, die sogenannten Bände. Ganz ähnlich ist das Chromatin der großen und komplexen eukaryotischen Zellen unterteilt in Chromosomen.
Ohne die gesamte Rezeptesammlung (Genom) mit Tausenden Rezepten (Genen) kann keine Zelle lange leben. Die Chromosomen in einem Zellkern sind unterschiedlich groß und können Dutzende bis Tausende Gene (Bauanleitungen) für die Herstellung von Eiweißen und RNAs enthalten.
| Schema eines Bakteriums | |
|---|---|
 |
|
| Mariana Ruiz Villarreal, public domain | |
Auch Viren und Prokaryoten (Bakterien und Archäen) besitzen Chromosomen, aber sie verpacken ihr Erbmaterial nicht in Zellkernen. Bakterien können mit einem einzigen Chromosom auskommen, weil sie nur wenige Tausend Eiweiß-Rezepte (Gene) besitzen. Außerdem sind Bakterien-Zellen so klein, dass ihre Chromosomen von jedem Punkt der Zelle aus leicht erreichbar sind. Vielleicht müssen sie deshalb nicht in einem Zellkern konzentriert werden. Angesichts der häufigen Zellteilungen wäre aber auch das ständige Auf- und Abbauen eines Zellkerns für Bakterien extrem aufwändig.
Der Lerntext Endosymbionten-Theorie erklärt, wie sich Biologen heute die Entstehung der ersten eukaryotischen Zelle aus den beiden Arten von Prokaryoten (Bakterien und Archäen) vorstellen.
Die Gesamtzahl der Nukleotide im diploiden menschlichen Genom beträgt ungefähr 6,2 Milliarden. Insgesamt ergeben sie eine Länge von mehr als 2 Metern pro Zelle. Weil diese Länge extrem unhandlich wäre, ist unser Genom aufgeteilt auf normalerweise 46 Untereinheiten, die man Chromosomen nennt. Diese Chromosomen sind unterschiedlich lang und wenn man sie kurz vor einer Zellteilung (in der mitotischen Metaphase) anfärbt, erkennt man unterschiedliche Streifenmuster. Fotografiert man die angefärbten Chromosomen, dann kann man sie aus dem Foto ausschneiden, nebeneinander legen und vergleichen. Man nennt das ein Karyogramm.
Normalerweise zeigt sich dabei, dass die Chromosomen in weiblichen Zellen 23 und in männlichen Zellen 22 Chromosomenpaare gleich aussehender Chromosomen bilden. Man nennt sie auch homologe (sich entsprechende) Chromosomen oder homologe Chromosomenpaare. Dabei kommt immer ein Chromosom eines Chromosomenpaares vom Vater und das andere von der Mutter. Das 23. (nur bei Männern ungleiche) Chromosomenpaar bestimmt das Geschlecht eines Menschen. Darum heißen seine Chromosomen auch Geschlechtschromosomen oder Gonosomen. Bei Frauen besteht dieses Chromosomenpaar aus zwei großen X-Chromosomen. Bei Männern sind es ein großes X-Chromosom und ein viel kleineres Y-Chromosom.
| Karyogramm eines Mannes |
|---|
 |
| National Human Genome Research Institute, public domain |
Menschen mit der Trisomie 21 oder der Trisomie X besitzen in den Zellkernen ihrer normalen Körperzellen (Reife rote Blutkörperchen besitzen keinen Zellkern mehr.) ein zusätzliches Chromosom, welches ihr Leben nicht erleichtert.
Zellkerne menschlicher Geschlechtszellen (Spermien und Eizellen) enthalten nur 23 Chromosomen. Eizelle und Spermium heißen Geschlechtszellen, weil sie für die geschlechtliche (sexuelle) Fortpflanzung benötigt werden. Die 23 Chromosomen der Geschlechtszellen nennt man den einfachen oder haploiden Chromosomensatz und auch alle Zellen mit dem einfachen Chromosomensatz heißen haploid. Die Geschlechtszellen eines Menschen enthalten unterschiedliche Mischungen der Baupläne seiner beiden Eltern.
Die Chromosomen menschlicher Zellkerne enthalten Gene für rund 23.000 Proteine sowie sehr viele Kopiervorlagen für verschiedene Arten von RNAs, die als Bausteine und Werkzeuge unserer Zellen dienen. Von den allermeisten dieser Gene haben wir eine Kopie von der Mutter und eine fast identische vom Vater geerbt. In unseren normalen, noch lebenden Körperzellen kommt also unser Bauplan (Genom) in zweifacher Ausführung vor. Man nennt das einen diploiden Chromosomensatz und die Summe all dieser Gene nennt man Kerngenom. Zu den Genomen (Bauplänen) aller noch lebensfähigen tierischen Zellen zählt zusätzlich zum Kerngenom auch noch das Genom der Mitochondrien.
Ein neuer Mensch entsteht, wenn sich eine väterliche (Spermium) und eine mütterliche (Eizelle) Geschlechtszelle zu einer befruchteten Eizelle (Zygote) vereinigen. Nach der Vereinigung der Geschlechtszellen enthält die Zygote 23 mütterliche und 23 väterliche, also insgesamt 46 Chromosomen. Man spricht nun von einem doppelten oder diploiden Chromosomensatz und nennt auch den neuen Zellkern sowie die ganze Zygote diploid. Enthält der Zellkern der Zygote zwei X-Chromosomen, dann ist sie rein genetisch betrachtet weiblich. Enthält aber der Zellkern der Zygote ein X- und ein Y-Chromosom, dann kann sich der Embryo männlich entwickeln, falls alles gut geht. Der Zellkern der Eizelle enthielt normalerweise 23 Chromosomen, bei denen man zwischen 22 Autosomen und einem Gonosom (Geschlechtschromosom) unterscheidet. Das Gonosom der Eizelle ist immer ein relativ großes X-Chromosom. Auch der Zellkern des Spermiums enthielt 23 Chromosomen, aber sein Gonosom kann entweder ein relativ großes X-Chromosom oder ein nicht einmal halb so großes Y-Chromosom sein. Diesen Unterschied zwischen den menschlichen Gonosomen sieht man im folgenden elektronenmikroskopischen Bild.
| die Geschlechtschromosomen X&Y des Menschen |
|---|
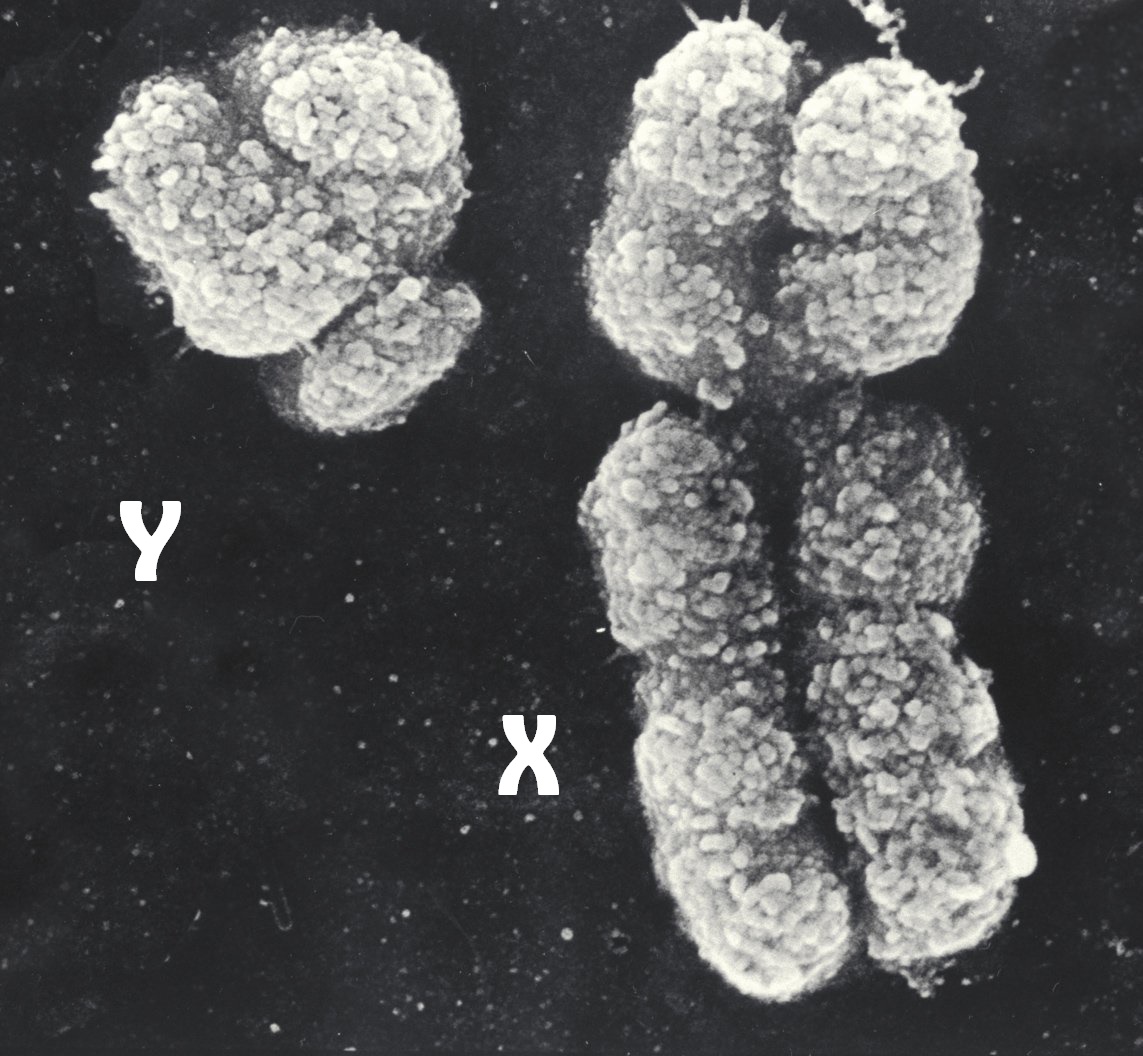 |
| Geo-Science-International, CC BY-SA 4.0 |
| Man sieht im elektronenmikroskopischen Bild zwei menschliche Geschlechtschromosomen in ihrer Transport-optimierten, maximal kondensierten Form. Jedes dieser Chromosomen ist ein Doppelchromosom oder 2-Chromatiden-Chromosom, weil es aus zwei Chromatide genannten, nahezu identischen Kopien besteht. Die Centromere erkennt man daran, dass an diesen Stellen die beiden Chromatiden eingeschnürt sind. |
Weil die Zellkerne von Frauen zwei X-Chromosomen enthalten, besitzen sie mehr DNA (und Allele) als Männer. Weil aber das Y-Chromosom dem X-Chromosom fehlende, einzigartige Gene enthält, besitzen Männer mehr Gene als Frauen. Wenn in menschlichen Geschlechtsorganen (Eierstöcken oder Hoden) Geschlechtszellen entstehen, dann reduziert eine Meiose genannte spezielle Art der Zellteilung die Zahl der Chromosomen auf nur noch 23. Dadurch wird verhindert, dass die Zellen der Kinder doppelt soviele Chromosomen wie die ihrer Eltern enthalten.
In Familien findet man häufig über Generationen hinweg auffällige Ähnlichkeiten hinsichtlich des Aussehens, bestimmter Gesichtsausdrücke und Körperhaltungen, aber auch bei Charakter, Verhalten, Fähigkeiten oder Anfälligkeiten für bestimmte Krankheiten. Das liegt daran, dass Eltern eine zufällig ausgewählte Hälfte ihrer Gene an ihre Kinder vererben. Deshalb nannte man sie früher auch Erbanlagen.
Die zufällige Auswahl der Gene geschieht während der Meiose. Sie sorgt für die genetische Variabilität bzw. genetische Vielfalt unter den Geschwistern und ist sehr wichtig für die Fähigkeit einer Spezies, sich an neue Umweltbedingungen anzupassen.
Die mütterliche Hälfte der Gene steckt in einer riesigen Eizelle, die außer dem Kerngenom auch die Organellen, das Zytoplasma und die Zellmembran mit ihren Rezeptor beisteuert. Das Spermium liefert kaum mehr als die väterlichen Chromosomen. Aber wenn es in die Eizelle eindringt, vereinigen sich zwei haploide zu einem einzigartigen diploiden Bauplan für einen neuen Menschen und die Zygote erhält den Impuls, die Embryonalentwicklung zu starten.
|
Ein Spermium dringt in eine Eizelle ein.
|
|---|
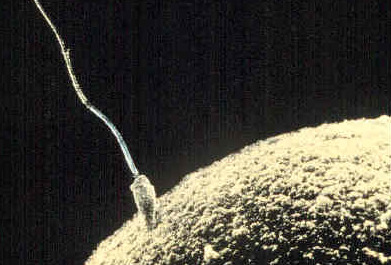
|
| anonym, Public domain |
Im Gegensatz zu manchen kochenden Menschen schreiben Zellen ihre Rezeptbücher (Genome) nicht einfach selbst. Genome werden von Mutterzellen an ihre beiden Tochterzellen vererbt oder die beiden Genome einer männlichen und einer weiblichen Geschlechtszelle vereinigen sich zum neuen Genom einer befruchteten Eizelle.
Bei jeder Zellteilung muss jede der beiden Tochterzellen einen eigenen Zellkern mit einer Kopie des kompletten Bauplans (Genoms) erhalten. Deshalb geht jeder Zellteilung eine Kernteilung (Mitose) voraus.
Die Kernteilung darf aber nicht dazu führen, dass sich die beiden neuen Zellkerne die Chromosomen teilen müssen. Denn dann hätte jede Tochterzelle nur noch halb soviele Chromosomen wie die Mutterzelle. Jede Tochterzellen muss von jedem Chromosom eine Kopie erhalten. Darum müssen vor jeder Kernteilung alle Chromosomen des Zellkerns der Mutterzelle verdoppelt werden. Diese Verdopplung der Chromosomen nennt man Replikation oder genauer DNA-Replikation.
Die DNA-Replikation erfogt im Zellzyklus zwischen einer Zellteilung und der nächsten Kernteilung in der sogenannten S-Phase (Synthese-Phase).
Der Lerntext Zellbiologie erklärt im Detail den Zellzyklus mit der DNA-Replikation, der Mitose oder der Meiose in den Kapiteln:
Die beiden Kopien eines Chromosoms heißen Chromatiden. Durch die DNA-Replikation entsteht aus einem 1-Chromatid-Chromosom ein 2-Chromatiden-Chromosom (Doppelchromosom). Aber die beiden Chromatiden bleiben zunächst an einer Centromer genannten Stelle miteinander verbunden. Nach der DNA-Replikation kann die Kernteilung erfolgen.
Solange zwischen den Kernteilungen der Zellkern existiert, bleiben die Chromosomen eukaryotischer Zellen in ihm eingeschlossen. Die folgende Animation zeigt, wie zunächst die 1-Chromatid-Chromosomen durch die DNA-Replikation zu 2-Chromatiden-Chromosomen verdoppelt werden. Danach kommt es zur Kernteilung (Mitose). Schließlich teilt sich die eukaryotische Mutterzelle in zwei Tochterzellen.
Der wichtigste Bestandteil eines Chromosoms ist ein extrem langes Molekül namens Desoxyribonukleinsäure (DNS), das wie eine spiralig verdrehte Strickleiter aussieht. Auf Englisch nennt man es Desoxyribonucleic Acid. Daher kommt die international übliche Abkürzung DNA. In den Chromosomen der Eukaryoten wird die DNA von Eiweißen kontrolliert und immer in die gerade passende Form gebracht.
Das folgende Schema deutet an, wie in Chromosomen die DNA um sogenannte Histon-Proteine gewickelt ist und wie massiv die normalerweise extrem langen und dünnen Chromosomen zu Beginn (in der Prophase) der Mitose zu dicken, kurzen und dadurch transportfähigen Knubbeln aufgewickelt und gerafft (kondensiert) werden.
| Schema zur Kondensierung eines Chromosoms |
|---|
 |
| NIH, Armin Kübelbeck, CC BY-SA 3.0 |
Die Verdopplung eines Chromosoms erfolgt hauptsächlich durch das DNA-Replikation genannte Kopieren oder Verdoppeln der darin enthaltenen DNA. Im Detail wird die DNA-Replikation im Lerntext Zellbiologie erklärt. Während der DNA-Replikation müssen die Chromosomen ganz lang und entknäuelt sein, weil sie sonst nicht kopiert werden könnten. Aber während der Kernteilung müssen sie transportiert werden. Und es wäre extrem aufwändig, in einer winzigen Zelle ein vielfach längeres Chromosom vollständig in eine Ecke zu ziehen. Zu Beginn der Mitose muss daher jedes Chromosom ganz eng zusammen geknäuelt werden. In dieser kondensierten Transportform sieht man die Chromosomen oben im oberen Drittel des Schemas.
Insgesamt enthalten die 46 Chromosomen in den Zellkernen menschlicher Körperzellen gut sechseinhalb Milliarden Basenpaare, die vor einer Mitose alle kopiert werden müssen. Trotz dieser enormen Menge wäre es vermutlich möglich, perfekte Kopien zu machen. Das tun Zellen aber nicht. Ihre Kopierwerkzeuge arbeiten nicht vollkommen perfekt, weil alle Lebewesen mit perfekt arbeitenden Kopierwerkzeugen ausgestorben sind. Man nennt die zufällig auftretenden Kopierfehler Mutationen und ohne Mutationen könnten sich Spezies nicht an veränderte Umwelten anpassen.
Ursächlich für unterschiedliches Aussehen verschiedener Spezies sind etwas unterschiedliche Varianten ihrer Proteine. Und die Ursache für die Unterschiede zwischen verschiedenen Varianten eines Proteins sind Unterschiede zwischen ihren Bauplänen, also den Genen. Genauer gesagt sind es Varianten (Allele) des selben Gens.
Menschen erben ihre Gene von ihren Eltern. Normalerweise haben Frauen von allen und Männer von fast allen ihren Genen zwei Kopien - eine vom Vater und eine von der Mutter. Unsere Eigenschaften sind deshalb eine Mischung der Eigenschaften der jeweiligen Mütter und Väter. Dabei können die Einflüsse der mütterlichen und väterlichen Genvarianten (Allele) gleich oder unterschiedlich groß sein. Kommt von einem Elternteil eine intakte Genvariante und vom anderen Elternteil ein funktionsloses Allel, dann setzt sich das intakte durch. Man nennt es dominant. Defekte Allele, die keine funktionsfähigen Proteine codieren, heißen rezessiv.
| Schema eines dominant-rezessiven Erbgangs |
|---|
 |
| Magnus Manske, public domain |
| Das Schema veranschaulicht die ersten beiden mendelschen Regeln anhand eines dominant-rezessiven Erbgangs, wobei das Allel für eine rote Blütenfarbe dominant ist. Ein defektes Allel dieses Gens führt zu einer weißen Blütenfarbe. Dieses Merkmal ist jedoch rezessiv, weil das defekte Allel durch das intakte ersetzt werden kann. (1) Elterngeneration mit reinerbigen Anlagen (w/w oder R/R). (2) F1-Generation: Alle Individuen sehen gleich aus, die dominante rote Erbanlage setzt sich gegen die rezessive weiße durch. (3) F2-Generation: Dominante (rot) und rezessive (weiße) Erscheinungsformen zeigen ein Verhältnis von 3:1. |
Sind beide Allele gleich dominant, dann führt das zu folgendem Erbgang.
| Schema eines intermediären Erbgangs |
|---|
 |
| Magnus Manske, public domain |
| Das Schema veranschaulicht die ersten beiden mendelschen Regeln anhand eines intermediären Erbgangs, wobei die Kombination beider Allele eine Mischfarbe egibt. (1) Elterngeneration mit reinerbigen Anlagen (w/w oder R/R). (2) F1-Generation: Die Blütenfarbe aller Individuen ist rosa. (3) F2-Generation: Rote, rosa und weiße Blüten zeigen ein Verhältnis von 1:2:1. |
Das folgende Schema veranschaulicht die dritte mendelsche Regel mit zwei unabhängig voneinander vererbten Merkmalen. Unten in der Tabelle sieht man, wie sich die Merkmale auswirken. Man nennt diese äußerlich erkennbaren Merkmale den Phänotyp. Phänotypisch unterscheidbar sind die Merkmale Farbe (grün oder gelb) und Form (glatt oder wellig) der Bohnen. Die Tabelle zeigt für den Fall zweier hinsichtlich beider Merkmale mischerbiger Eltern die relativen Häufigkeiten der Merkmalskominationen unter den Nachkommen.
Über der Tabelle und mit den Buchstaben auch in ihr zeigt das Schema die genotypische Erklärung, also die nicht direkt sichtbare Ebene der Gene. Man sieht Zellen mit größeren und etwas kleineren Chromosomen. Die größeren Chromosomen enthalten ein Gen, welches die Farbe der Bohne beeinflusst. Die kleineren Chromosomen enthalten ein Gen, welches die Form der Bohne beeinflusst. Von jedem der beiden Gene gibt es zwei Varianten (Allele), wobei jeweils die groß geschriebene dominant ist und sich gegenüber dem klein geschriebenen rezessiven Allel durchsetzt. Das Allel R bewirkt eine grüne Färbung. Das rezessive Allel r bewirkt eine gelbe Färbung, sofern es nicht durch ein Allel R dominiert wird. Analog lässt das dominante Allel Y die Bohne wellig wachsen, während das rezessive Allel y für eine glatte Bohne sorgt, wenn es nicht von Y dominiert wird.
Gemäß der dritten mendelschen Regel werden die beiden Merkmale unabhängig voneinander vererbt, weil sie auf verschiedenen Chromosomen untergebracht sind. Lägen die beiden Gene direkt nebeneinander im selben Chromosom, dann würden sie fast nie unabhängig voneinander verberbt.
| Schema zur Unabhängigkeitsregel |
|---|
|
Ganz oben unter der Überschrift Meiose zeigt das Schema zwei (diploide) Körperzellen der Elterngeneration (F1-Generation). Man sieht in jeder Zelle zwei größere und zwei etwas kleinere Chromosomen, von denen jeweils eines von der Mutter und eines vom Vater stammt. Die größeren Chromosomen enthalten ein Gen (R oder r), welches die Farbe der Bohne beeinflusst. Die kleineren Chromosomen enthalten ein Gen (Y oder y), welches die Form der Bohne beeinflusst. Beide Körperzellen sind hinsichtlich beider Gene mischerbig. Das bedeutet, dass jeweils das vom "Großvater" stammende Chromosom ein anderes Allel das von der "Großmutter" stammende enthält. Weil sich jeweils das dominante Allel durchsetzt, sind die Bohnen der in diesem Experiment als Vater und Mutter eingesetzten Elternpflanzen alle grün und wellig. In der zweiten Zeile sieht man, das alle Chromosomen (durch DNA-Replikation) verdoppelt wurden. Die beiden Kopien (Chromatiden) hängen aber (an den Centromeren) noch zusammen. Es folgt die erste meiotische Zellteilung, in welcher jede (der haploiden) Tochterzelle von jedem Chromosomenpaar nur entweder das großväterliche oder das großmütterliche Chromosom erhält. Das Ergebnis dieser ersten meiotischen Zellteilung sieht man in der dritten Zeile mit vier (haploiden) Tochterzellen. Abgeschlossen wird die Bildung von in diesem Fall weiblichen Geschlechtszellen (Eizellen) durch die zweite meiotische Zellteilung. Dabei werden die beiden Kopien (Schwesterchromatiden) jedes Chromosoms voneinander getrennt und jede der Tochterzellen in der vierten Zeile erhält von jedem Chromosom nur eine Kopie (Chromatid). Insgesamt verfügt dadurch jede Geschlechtszelle (Gamete) von jedem Chromosom und im Prinzip auch von jedem Gen nur noch jeweils eine Kopie. Und weil die Körperzellen hinsichtlich beider Gene mischerbig waren, enthalten nun die Geschlechtszellen unterschiedliche Allelkombinationen. |
 |
| Mariana Ruiz Villarreal, gemeinfrei |
|
Unten zeigt die Tabelle alle möglichen Kombinationen der vier Allele, die durch Befruchtung der Eizellen durch genauso entstandene männliche Geschlechtszellen in der Generation der Nachkommen (F2-Generation) entstehen können. |
Werden bei einem Heterozygoten die Genprodukte beider Allele unabhängig voneinander ausgeprägt, spricht man von Kodominanz bzw. von kodominanter Vererbung. Das bekannteste Beispiel für Kodominanz findet sich beim Blutgruppensystem AB0: Die Allele A und B kommen beim Genotyp AB beide zur Ausprägung, so dass auch der Phänotyp AB lautet. Das Gen zur Ausprägung der Blutgruppen des AB0-Systems liegt auf dem Chromosom 9. Beispiele für intermediäre Erbgänge sind die rosafarbenen Blüten von Primeln, Löwenmäulchen oder ursprünglich mittelamerikanischen Wunderblume, weil das Merkmal Weiß auf zwei von Vater und Mutter geerbten defekten Allelen ohne Genprodukt beruht und ein intaktes Allel allein nicht ausreicht, um genügend roten Farbstoff für rote Blüten zu produzieren. Kreuzt man zwei jeweils homozygot weiße und rote Exemplare dieser Blütenpflanzen miteinander, dann findet man in der nächsten Generation nur rosafarbene Blüten.
Es gibt bei den seit mehr als 170 Jahren als Haustiere gezüchteten Wellensittichen zahlreiche Farbvarianten. Um es nicht unnötig kompliziert zu machen, möchte ich mich darauf beschränken, die Vererbung von zwei an der Farbgebung beteiligten Genen mit jeweils 2 Allelen zu erklären.
Das eine Gen ist ein Rezept für die Produktion eines Proteins, welches normalerweise zur Herstellung des dunklen Farbstoffs Eumelanin führt. Zusammen mit der normalen Struktur der Federn bewirkt dieser Farbstoff eine Blaufärbung. Es gibt aber ein mutiertes Allel (b) dieses Gens, das zu einem defekten Protein führt. Dieses nicht funktionsfähige Protein kann keinen Beitrag zur Herstellung des Farbstoffs leisten. Wenn der Vogel auch von seinem anderen Elternteil kein intaktes Allel (B) dieses Gens geerbt hat, dann kann er gar keinen Farbstoff für die Blaufärbung produzieren.
Das andere Gen codiert ein Protein, welches für die Produktion des gelben Farbstoffes Psittacin benötigt wird. Auch von diesem Gen gibt es außer dem funktionsfähigen (G) noch ein funktionsunfähiges mutiertes Allel (g).
Betrachten wir mit diesem Vorwissen die Kreuzung eines reinerbig grünen (BBGG) mit einem reinerbig weißen (bbgg) Wellensittichs, dann enthalten alle Geschlechtszellen des einen Elternteils die beiden dominanten Allele B und G, während alle Gameten des anderen Tieres die rezessiven Allele b und g enthalten. Bei den Nachkommen ergeben sich folgende Kombinationsmöglichkeiten:
| F1 | bg | bg |
| BG | BbGg | BbGg |
| BG | BbGg | BbGg |
Alle Nachkommen in der F1-Generation sind genotypisch und phänotypisch gleich. Alle sind grün. Sie sind aber auch alle mischerbig. Deshalb produzieren sie im Hinblick auf diese beiden Gene 4 unterschiedliche Sorten von Geschlechtszellen: BG, Bg, bG und bg.
| F2 | BG | Bg | bG | bg |
| BG | BBGG | BBGg | BbGG | BbGg |
| Bg | BBGg | BBgg | BbGg | Bbgg |
| bG | BbGG | BbGg | bbGG | bbGg |
| bg | BbGg | Bbgg | bbGg | bbgg |
In der F2-Generation findet man also die Farben Grün, Blau, Gelb und Weiß im Verhältnis: 9:3:3:1.

Der Lerntext Biomoleküle liefert Informationen zu den Themen:
Der Lerntext Biomoleküle liefert auch Informationen zu den Themen:
Doppelsträngige DNA ist ein unglaublich langes Riesenmolekül, das wie eine spiralig verdrehte Strickleiter aussieht. Zusammen mit zahlreichen Proteinen bildet die DNA Chromosomen, die einen (1-Chromatid-Chromosom) oder zwei (2-Chromatiden-Chromosom oder Doppelchromosom) DNA-Doppelstränge enthalten können. Vergleicht man die Gesamtheit der im Zellkern gespeicherten Erbinformationen mit einem großen Lexikon, dann entsprechen die Chromosomen den einzelnen Bänden, in welche das Lexikon aufgeteilt wurde, damit es handhabbar bleibt.
Der in DNA gespeicherte Bauplan (Genom) befindet sich bei noch teilungsfähigen eukaryotischen Zellen im Zellkern und Mitochondrien. Die genetische Information eines Gens steckt in der Reihenfolge (Sequenz) der Nukleotide, so wie sich die Bedeutung eines Wortes aus der Reihenfolge seiner Buchstaben ergibt. Und wie die wertvollsten Bücher einer Bibliothek nur fotografiert oder photokopiert und nicht ausgeliehen werden, so verlässt auch die DNA nicht den Zellkern. Braucht eine Zelle ein Rezept (Gen) für ein bestimmtes Protein, dann werden im Zellkern von dem entsprechenden Gen in einem Transkription genannten Prozess Umschriften (Kopien auf den etwas anderen Informationsträger RNA) gemacht.
Die Informationen werden nicht einfach kopiert, weil die RNA etwas andere Nukleotide als die DNA enthält. Das Kapitel: "Nukleotide sind die Monomere der Nukleinsäuren." im Lerntext Biomoleküle zeigt die feinen Unterschiede zwischen den Desoxyribonukleotiden der DNA und den Ribonukleotiden der RNA. Es passiert also eher ein Umschreiben wie die Übertragung eines in kyrillischer Schrift vorliegenden Originals in einen Text mit lateinischen Buchstaben. Deshalb heißt das Umschreiben einer Bauanleitung aus einer DNA-Sequenz in eine RNA-Sequenz Transkription.
Ein erheblicher Teil der Transkripte wird direkt als RNA-Enzyme, regulatorische RNAs, rRNA oder tRNAs gebraucht. Die übrigen Transkripte werden im Zellkern noch bearbeitet (prozessiert) und verlassen dann als mRNAs durch die Kernporen den Zellkern in Richtung Cytoplasma. Die Abkürzung mRNA steht für messenger-RNA oder auf deutsch Boten-RNA.
Die mRNAs binden im Cytoplasma an Ribosomen, die mit Hilfe sogenannter tRNAs fähig sind, die von den mRNAs codierten Proteine zu synthetisieren. Diese Übersetzung einer Nukleotidsequenz in eine Aminosäuresequenz nennt man Translation.
Proteine können einfach Bausteine unseres Körpers, Rezeptoren, Antikörper, Kanäle, Pumpen oder Enzyme sein. Alle diese Proteine beeinflussen das Aussehen oder die Fähigkeiten eines Lebewesens und teilweise unterscheiden sie sich von Spezies zu Spezies und von Rasse zu Rasse.
Im Zytoplasma schwimmen die großen und kleinen Untereinheiten der Ribosomen herum. An eine mRNA bindet zunächst die kleine und danach auch die große Untereinheit eines Ribosoms. Ribosomen sind biologischen Nanomaschinen für die Protein-Synthese. In einem Translation genannten Prozess übersetzen Ribosom mit Hilfe der tRNAs die Nukleotidsequenz der mRNA in die Aminosäure-Sequenz eines Proteins, welches in diesem Fall das Genprodukt ist. Ein Übersetzungsprozess (Translation) ist notwendig, weil den 20 verschiedenen Aminosäuren der Eiweiße nur jeweils 4 Sorten von Nukleotiden in DNA und mRNA gegenüberstehen. Deshalb werden sogenannte Tripletts aus je 3 Nukleotiden benötigt, um eine Aminosäure zu codieren. Die sogenannte Codonsonne zeigt, welche Tripletts für welche Aminosäuren stehen.
Am Anfang (5'-Ende) der mRNA findet ein Ribosom eine Erkennungs-Nukleotidsequenz, die ihm mitteilt, ob das zu synthetisierende Protein im Cytoplasma bleiben, in eine Membran eingebaut oder aus der Zelle exportiert werden soll. Soll das neue Protein in der Zelle bleiben, wird es vom Ribosom einfach mitten im Zytoplasma produziert. Ansonsten wandert das Ribosom mit der mRNA zum endoplasmatischen Retikulum und synthetisiert das Protein in die Membran oder in den Innenraum des endoplasmatischen Retikulums hinein. Dabei muss die Reihenfolge der 4 Nukleotide der mRNA übersetzt werden in die Sequenz der 20 unterschiedlichen Aminosäuren (Aminosäuresequenz), aus denen ein Protein bestehen kann. Deshalb nennt man diesen Vorgang am Ribosom einfach Translation (Übersetzung). Im Folgenden werden die Transkription und die Translation genauer dargestellt.
Die Bauanleitung heißt Gen und besteht aus einem Material namens DNA (Desoxyribonucleic Acid) oder auf Deutsch DNS für Desoxyribonukleinsäure. Seine Informationen stecken in der Reihenfolge (Sequenz) der Desoxyribonukleotide genannten Monomere der DNA. Meistens vor den codierenden gibt es in der DNA auch noch regulatorische Sequenzen. An ihnen binden Moleküle aus der eigenen und vielen anderen Zellen, welche die Transkription einzelner Bauanleitungen (Gene) fördern oder verhindern.
Benötigt eine eukaryotische Zelle eine bestimmte RNA oder eine Eiweiß-Sorte, dann werden im Zellkern Kopien des DNA-Abschnittes mit der entsprechenden Bauanleitung (codierende DNA-Sequenzen des Gens) gemacht.
Die Kopien bestehen nicht aus DNA, sondern aus der chemisch etwas anderen RNA, die auf Deutsch Ribonukleinsäure (RNA) heißt. Fachleute sprechen deshalb meistens nicht von Kopieren, sondern von Transkription (Umschreiben). Und weil die RNAs wie Boten die Bauanleitung aus dem Zellkern ins Cytoplasma transportieren, nennt man sie Boten-RNA oder kurz mRNA (messenger RNA). Nach der Bauanleitung einer mRNA werden im Cytoplasma oder ins endoplasmatischen Retikulum durch Ribosomen viele Proteine produziert. Ein Ribosom übersetzt (Translation) die Bauanleitung einer mRNA in die Aminosäure-Sequenz eines Proteins.
Damit ein Gen umgeschrieben werden kann, muss zunächst die DNA-Doppelhelix entspiralisiert und dann der DNA-Doppelstrang auf einer kurzen Strecke von 10-20 Nukleobasen so geöffnet werden, dass zwei DNA-Einzelstränge entstehen. An diesen beiden DNA-Einzelsträngen finden frei im Zellkern treibende RNA-Nukleotide passende Partner für Basenpaarungen. Aber nur an einem der beiden DNA-Einzelstränge verbindet der Enzym-Komplex DNA-abhängige RNA-Polymerase die über Wasserstoffbrückenbindungen gebundenen Nukleotide zu einem RNA-Transkript. Diesen als Vorlage für die RNA genutzten DNA-Einzelstrang nennt man DNA-Matrizenstrang.
Das folgende Schema zeigt, wie die beiden Stränge einer DNA-Doppelhelix durch eine RNA-Polymerase getrennt werden und an einem DNA-Strang eine RNA-Kopie entsteht.
| Schema der Transkription | |
|---|---|
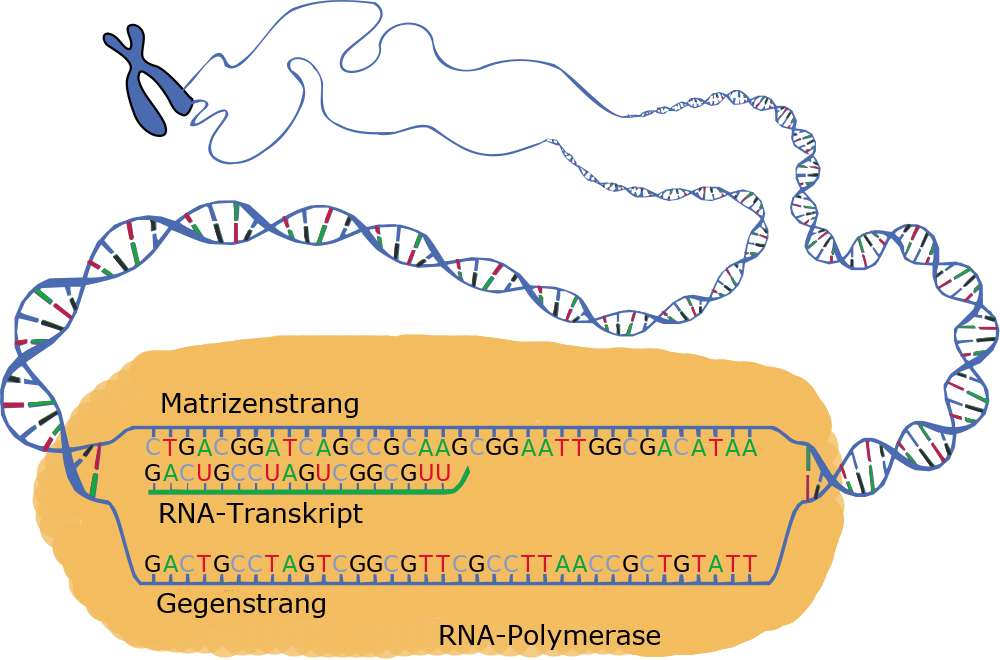 |
|
| Roland Heynkes, CC BY-SA-4.0. Ich habe nur die Größe der RNA-Polymerase korrigiert und ein Schema ins Deutsche übersetzt, das von einem anonymen Zeichner als public domain der Wikimedia zu Verfügung gestellt wurde. Das Schema der Transkription zeigt, wie sich der DNA-Doppelstrang öffnet und sich mit Hilfe des Enzyms RNA-Polymerase ein RNA-Gegenstrang bildet. Die Transkription beginnt am Promotor und endet am Terminator. | |
Nicht schön, aber Schritt für Schritt erklärt das folgende Schema, wie die Transkription funktioniert:
 |
|
| Roland Heynkes, CC BY-SA-4.0 | |
Die folgende Grafik zeigt einen RNA-Polymerase-II-Initiation-Complex mit 9 Nukleotiden RNA in der Cartoon-Darstellung.
| RNA-Polymerase-II-Initiation-Complex mit 9 Nukleotiden RNA (3S17) | |
|---|---|
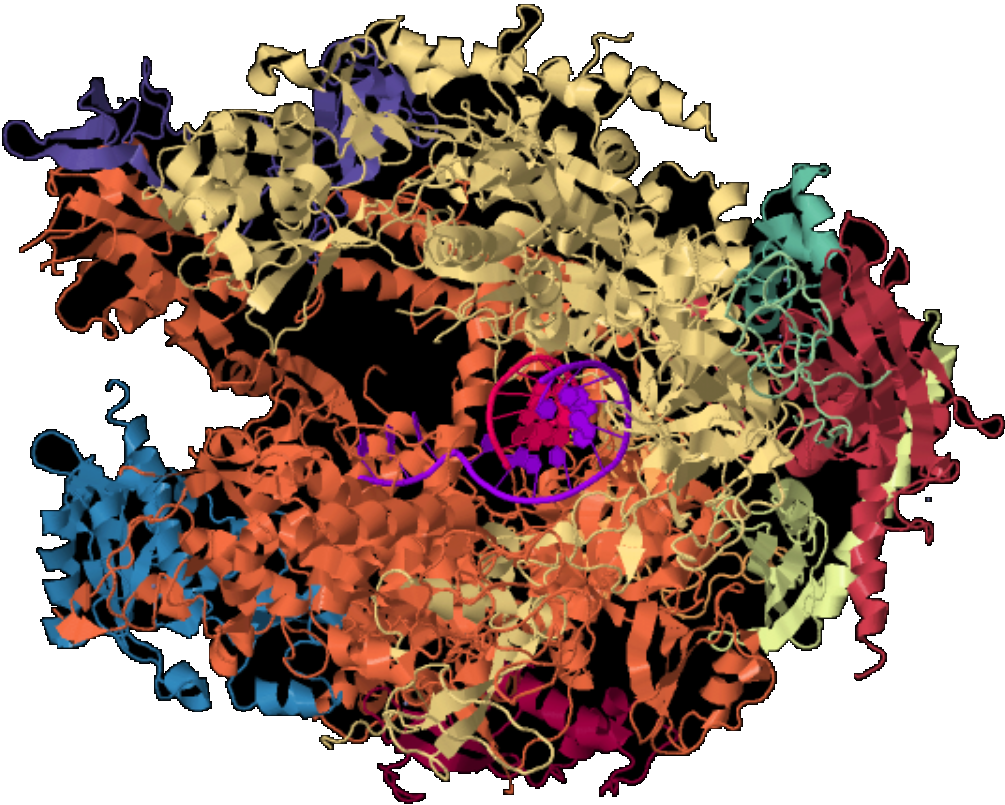 |
|
| Roland Heynkes, CC BY-NC-SA 4.0 | |
| Das einfach als screenshot in der Protein Data Bank produzierte Bild zeigt in unterschiedlichen Farben die verschiedenen Proteine des Enzym-Komplexes. Klickt man hier oder auf das Bild, dann kann man sich in einer 3D-Darstellung den Enzym-Komplex von allen Seiten und in verschiedenen Darstellungen ansehen. | |
Nach der Bauanleitung einer mRNA werden im Cytoplasma oder am endoplasmatischen Retikulum durch Ribosomen viele Proteine produziert. Ein Ribosom übersetzt (Translation) die Bauanleitung einer mRNA in die Aminosäure-Sequenz eines Proteins.
Der Sinn eines deutschen Satzes ergibt sich aus der Reihenfolge seiner Buchstaben. Genauso steckt auch der Informationsgehalt der Nukleinsäuren DNA und RNA in den Reihenfolgen (Sequenzen) ihrer Nukleobasen. Der gemeinte Sinn einer Buchstaben-Sequenz erschließt sich aber erst, wenn man weiß, wo die einzelnen Wörter beginnen und enden. So kann man beispielsweise aufgrund des fehlenden Leerzeichens nicht wissen, ob die Buchstaben-Sequenz: "kleineregel" kleiner Egel oder kleine Regel bedeuten soll. Beim alten deutschen Wort: "Wachstube" erschließt sich nur durch die Aussprache oder durch den Zusammenhang, ob es um eine Stube oder um eine Tube geht. Solche Interpretationshilfen gibt es bei DNA-Sequenzen nicht, aber dafür bestehen in ihr alle Wörter aus genau 3 Buchstaben, den sogenannten Tripletts. Meistens bezeichnet man diese Tripletts als Codons, weil sie etwas codieren. Jeweils 3 Basen stehen für (codieren) 1 von 20 verschiedenen Aminosäuren, aus denen unsere Proteine bestehen. Bestünden die Codons nur aus 2 Nukleotiden, dann gäbe es nur 4 mal 4 oder 4 hoch 2 mögliche und damit zu wenige Kombinationen. Die sogenannte Codonsonne zeigt von innen nach außen gelesen, welches Triplett für welche Aminosäure steht.
|
Codonsonne nennt |
 |
Das funktioniert aber nur, wenn klar ist, wo sich die Grenzen zwischen den Codons befinden. Aufgrund der immer gleichen Länge von 3 Nukleotiden ergeben sich glücklicherweise alle weiteren Codons, wenn man das die erste Aminosäure eines Proteins codierende Startcodon kennt. Und das ist kein Problem, weil das Startcodon in einer mRNA das die Aminosäure Methionin codierende Triplett AUG ist. Man kann sich daher den Beginn der Translation so vorstellen, dass ein Ribosom an einer mRNA entlang gleitet, bis es das Startcodon AUG gefunden hat.
tRNA mit einem grauen Anticodon unten und einer gelbgrünen Andockstelle für eine Aminosäure rechts oben. |
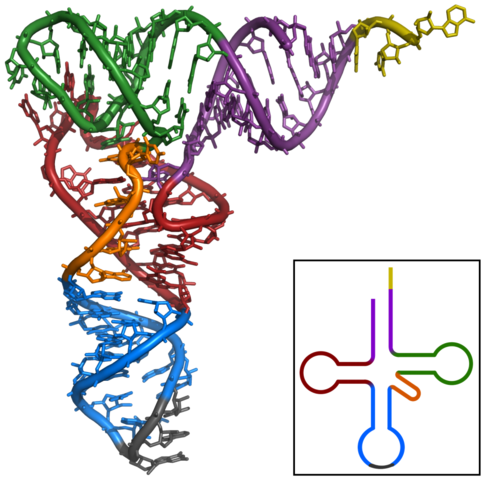 |
| anonym, CC BY-SA 3.0 |
| Auf einer Internetseite der internationalen Protein Data Base kann man ein dreidimensionales Modell einer tRNA unterschiedlich darstellen und von allen Seiten betrachten. |
| tRNA |
|---|
| Im großen Feld über diesem Text sind im WRL-Format aus der internationalen Protein Data Bank geladenen Koordinaten eingebunden. Sie können angezeigt und bewegt werden, wenn im Browser ein Plugin (Ergänzungsmodul) wie "Cosmo Player", "Cortona3D Viewer" oder "BS Contact" eingebunden ist. Es gibt auch spezielle Browser, die selbst WRL-Dateien anzeigen können. |
| Hier findet man eine langsamere, aber auch kompatiblere 3-D-Darstellung einer Hefe-tRNA mit dem JavaScript-Object JSmol und HTML 5. |
An das Startcodon bindet eine tRNA, an deren unterem Ende ein Anticodon genanntes Nukleobasen-Triplett (UAC) nach dem Schlüssel-Schloss-Prinzip perfekt zu dem Startcodon passt.
Hier geht es zu einer drehbaren 3-D-Darstellung einer Codon-Anticodon-Kontaktstelle mit dem JavaScript-Object JSmol und HTML 5.
Am oberen Ende der tRNA hängt die Aminosäure Methionin. Direkt daneben am Ribosom bindet an das folgende Codon eine weitere tRNA mit einem passenden Anticodon. Und wieder hängt oben an der tRNA die Aminosäure, die laut Codonsonne dem Codon in der mRNA entspricht.
| Translation an einem Ribosom |
|---|
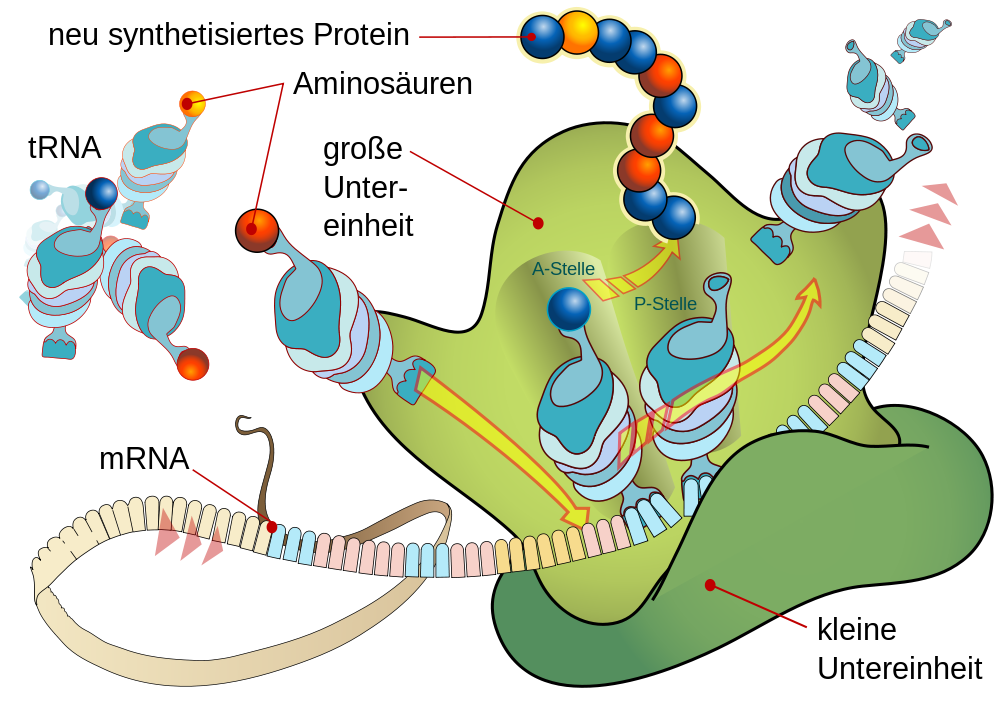 |
Dieses phantastische, von Matthias M. unter die Creative-Commons-Lizenz gestellte und damit kostenlos für unser Lernen verfügbare Schema der Translation erklärt im Grunde schon alles, was wir über die Translation wissen müssen. Eine tRNA nach der anderen versucht, am Ribosom mit ihrem aus 3 Nukleotiden bestehenden Anticodon an drei komplementäre Nucleotide der mRNA zu binden. Wenn ein Anticodon passt, dann wird die wachsende Aminosäurekette an die Aminosäure angehängt, die oben an der tRNA hängt. |
Ohne strukturelle Details konzentriert sich mein folgendes Schema auf die schrittweise Darstellung der Vorgänge in einem Zyklus.
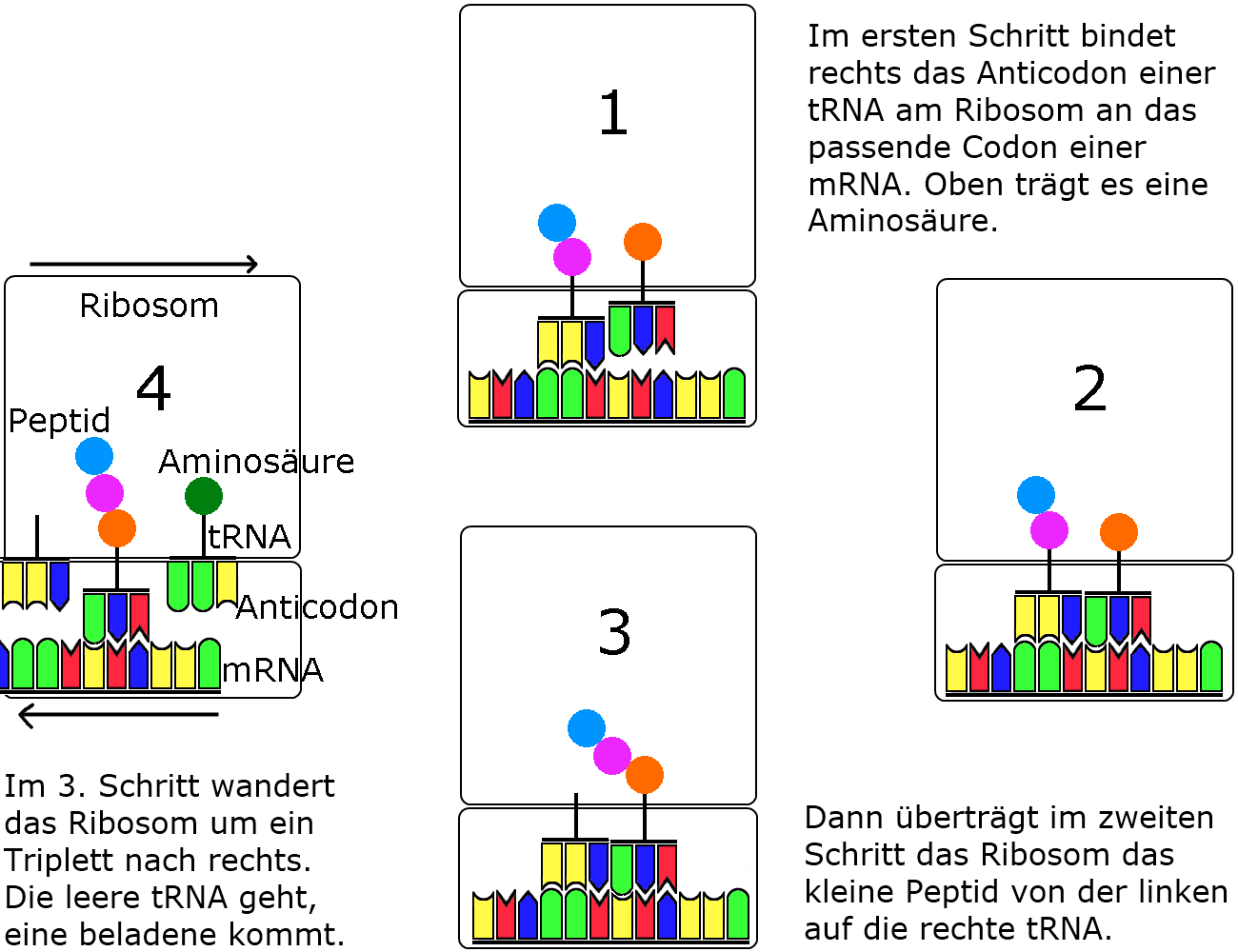 |
|
| Dieses Schema der Translation habe ich selbst gezeichnet. Es soll das Verständnis der Translation erleichtern, indem es das Anhängen einer Aminosäure als Kreislauf zeigt und dabei auch nachvollziehbar macht, wie dabei das Ribosom um 1 Triplett an der mRNA entlang wandert. Die tRNAs werden ganz auf das Anticodon und die Aminosäure-Bindungsstelle reduziert dargestellt, um die Sache übersichtlich zu halten. | |
Wie in den beiden Schemata gezeigt, hängt das Ribosom immer wieder das bereits produzierte Peptid an die nächste Aminosäure, bis die Translation mit einem Stoppcodon endet.
Die rote Umrandung des folgenden Abschnittes soll andeuten, dass die darin enthaltenen 8 Sätze kompakt zusammenfassen, was Lernende eigentlich schon am Ende der Sekundarstufe 1 über Genetik und Evolution wissen sollten. Spätestens in der Erprobungsstufe müssen diese 8 Sätze vollständig verstanden und sinngemäß gewusst werden.
|
Die folenden Begriffe werden von Schulbuchautoren gerne benutzt, in den meisten Fällen aber nicht erklärt. Weil das zu einer Diskriminierung von Lernenden mit Migrationshintergrund oder aus nichtakademischen Elternhäusern führt, erkläre ich sie an dieser Stelle.
|
Der High-School-Lehrer Paul Andersen hat zahlreiche Lehrvideos produziert, die man bei Bozemanscience und YouTube sehen kann. Zum Thema Genetik findet man von ihm unter anderem:
Das berühmte Massachusetts Institute of Technology (MIT) stellt seit 2002 Tausende Vorlesungen und Kurse kostenlos als sogenannte MIT OpenCourseWare auf seinen eigenen Internetseiten und bei YouTube zur Verfügung.
The Royal Society stellt zahlreiche Lernvideos über YouTube zur Verfügung. Darunter auch viele zum Thema Genetik.
Die Nobelpreisträgerin Elizabeth Blackburn (Department of Biochemistry an der University of California, San Francisco) erklärt in einer dreiteiligen Vorlesung (Part 1: The Roles of Telomeres and Telomerase, Part 2: Telomeres and telomerase in human cells and in cancer und Part 3: Stress, Telomeres and Telomerase in Humans) die Bedeutung der Telomere und Telomerase (Telomeres and telomerase: Their implications in human health an disease). Man findet diese Reihe und weitere Vorträge von Elizabeth Blackburn auch im Biologie-Portal iBiology.
Besonders Interessierte finden bei YouTube drei Genetik-Vorlesungen des Harvard-Professors und Nobelpreisträgers Jack Szostak: Part 1: The Origin of Cellular Life on Earth, Part 2: Protocell Membranes und Part 3: Non-enzymatic Copying of Nucleic Acid Templates aus der Sammlung von iBiology


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}